포켓몬 문제는 왜 다 이모양일까?
머릿말
최근 여자친구와 포켓몬스터 골드를 클리어하고, 포켓몬이 재밌어서 포켓몬 문제를 풀었다.
첫 BOJ 문제 풀이가 이 문제라니 기분이 오묘오묘.
설명의 파이썬 코드는 Markdown작성시 indent가 안이뻐서 따로 처리했습니다. 복붙시 인덴트를 다시 설정해야할 수도 있습니다.
문제 본문
HM과 TM
포켓몬에게 기술을 가르치려면 비전머신과 기술머신을 사용해야 한다.
비전머신은 총 8가지가 있고, HM01부터 HM08까지이다. 기술머신은 총 50가지가 있고, TM01부터 TM50까지이다.
비전머신과 기술머신의 목록이 주어졌을 때, 주어진 기술을 모두 배울 수 있는 포켓몬의 번호를 구하는 프로그램을 작성하시오.
포켓몬은 1번 이상해씨부터 151번 뮤까지만 존재한다고 가정한다.
입력
첫째 줄에 기술의 수 N (1 ≤ N ≤ 58)이 주어진다.
둘째 줄부터 N개 줄에는 기술의 이름이 주어진다. 비전머신은 HM01형태로, 기술머신은 TM01형태로 주어진다.
출력
첫째 줄에 입력으로 주어진 기술을 모두 배울 수 있는 포켓몬의 번호를 공백으로 구분해 출력한다. 포켓몬의 번호는 오름차순으로 출력한다.
입출력 예시
예제 입력 1
5
HM01
HM04
TM03
TM06
TM43
예제 출력 1
29 30 31 32 33 34 98 99 108 115 149 151
힌트
문제의 데이터는 포켓몬스터 파이어레드버젼을 기준으로 만들었고, http://pokemondb.net/pokedex/bulbasaur/moves/3를 참고했다.
문제
본 문제의 풀이는 2가지로 나뉜다.
- 포켓몬의 가능 스킬 데이터 DB만들기
- DB를 바탕으로 문제 해결
1. DB 만들기
A. 포켓몬 LIST crawling
본 사이트를 참고하였다니, 사이트에 대한 정보를 탐색해보자.
우선 사이트의 주소를 나눠보면
http://pokemondb.net/pokedex/ + bulbasaur + /moves/3 로 나눌 수 있다.
첫 번째는 사이트의 도메인, 두번째는 포켓몬 이름(한:이상해씨) + 마지막은 3세대 정보.
그렇다면 만약 사이트를 크롤링하기 위해서는 포켓몬 이름 리스트를 가지고 있어야 한다.
그렇기에 https://pokemondb.net/pokedex/all 에서 모든 포켓몬 정보를 가지고 와야한다.
하지만 처음에 이 사이트에 크롤링 결과 HTTP 404 Error가 발생한다. 구글링 결과 이는 이렇게 접속하는 방식이 일반 유저가 웹으로 접속함과 다르다는 이유로 크롤링을 막는 것이다.
이에 대한 해결 법은 웹페이지가 접속할때와 같은 HTTP request를 보내면 된다. 자세한 사항은 아래 코드를 참고하자.
여기서 마우스 우클릭 후, Inspect 를 해서 페이지 구조를 보면
<a class="ent-name" href="/pokedex/bulbasaur" title="View pokedex for #001 Bulbasaur">Bulbasaur</a>
포켓몬 명은 다음과 같이 a class= "ent-name"인 태그에 텍스트로 존재한다. 파싱해서 href내에 링크에 적혀있는 주소를 가져오면 더 좋겠지만, BeautifulSoup을 좀 더 편하게 사용하기 위해서 get_text()함수를 사용해서 포켓몬 이름을 가져왔다.
사이트를 살펴보면 번호가 같은 포켓몬들이 존재한다. 그렇기에 포켓몬이 겹치지 않게 포켓몬 번호를 파싱을 통해 가져와서 전 번호와 같은 포켓몬은 제외했다. 파싱의 경우에는 ‘#’을 ‘ ‘로 replace하고 split()하여 인덱스를 세서 7번쨰 값이 항상 포켓몬 번호임을 알 수 있었다.
또한 문제에서 151번 뮤까지만 입력을 받으니 조건문으로 탈출해주었다. 이제 후에 처리하기 위해 list에 저장하면 된다.
- 니드런 암수는 유니코드로 이름이 되어 있으나 실제 링크에서는 -m, -f로 되어있다. 그렇기에 utf-8으로 받고, 이를 replace해주어야한다.
- 마임맨의 경우에는 mr. mime이기에 “. “를 “-“로 replace해서 저장해주어야한다.
- 문제 풀이에 상관은 없지만 파오리도 이름에 ‘'‘가 포함되어 있으니, replace해주었다.
# coding: utf-8
import requests
from urllib.request import urlopen
from bs4 import BeautifulSoup
poke = list()
poke_skill = list()
SZ = 151
def poke_list_crawling():
global poke
global SZ
URL = "https://pokemondb.net/pokedex/all"
headers = {'User-Agent': 'Mozilla/5.0'} # like web browser
res = requests.get(URL, headers=headers)
bsObj = BeautifulSoup(res.text, "html.parser")
poke_list = bsObj.find_all("a","ent-name") # a class = "ent-name"
bf = -1
for i in poke_list:
li = str(i).replace('#', ' ').split() # pokemon index
if bf == int(li[6]):
continue
if int(li[6])>SZ: # MEW
break
bf = int(li[6])
poke.append(i.get_text().replace('♀','-f').replace('♂','-m').replace('. ','-').replace('\'',''))
B. 포켓몬에서 HM과 TM 받아오기
이제 포켓몬 리스트를 받아왔으니, 이 리스트로 또 각 포켓몬을 파싱해야한다.
우선 받아와야할 페이지의 이미지를 보자.
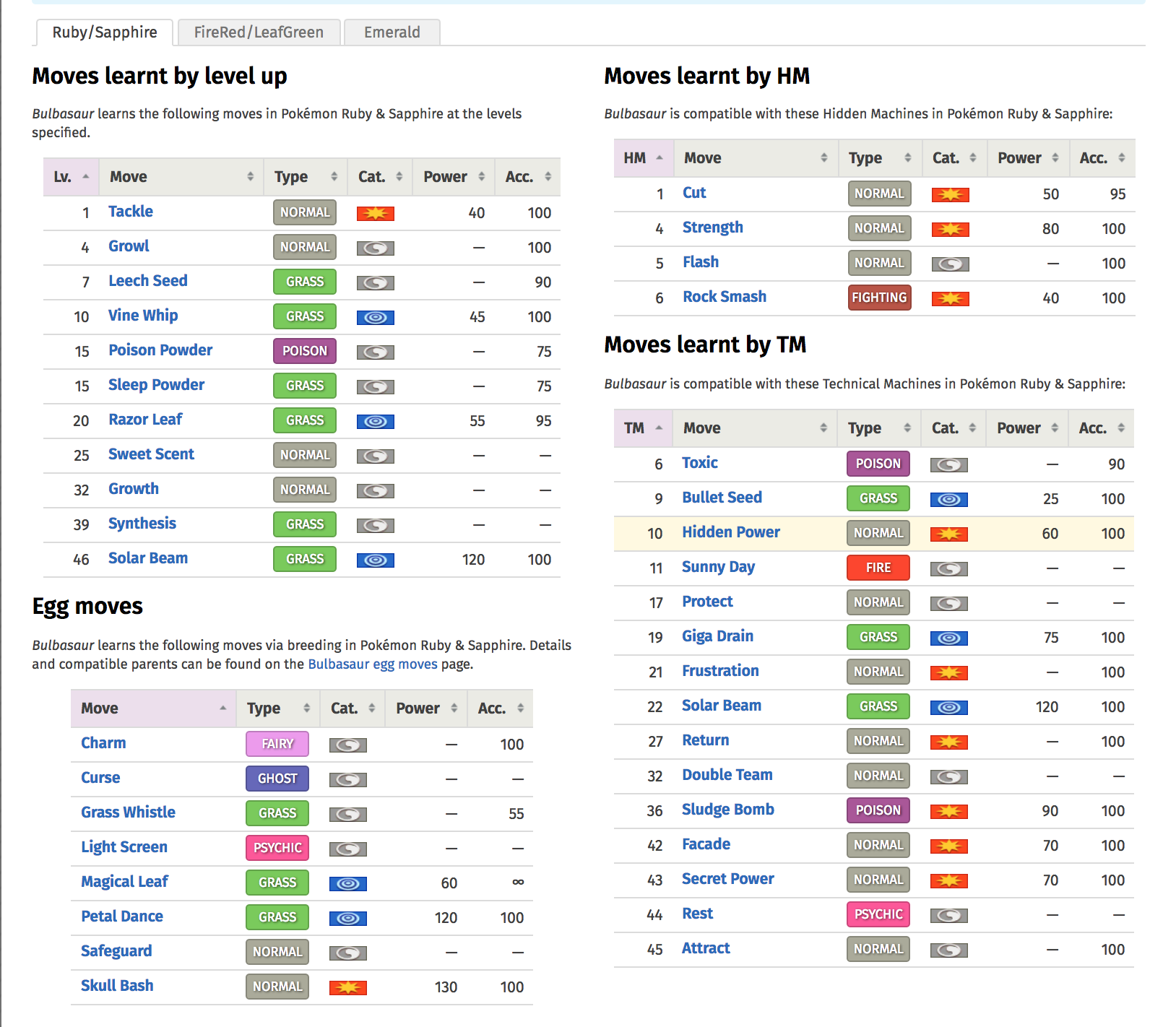
보는 것과 알 수 있듯이 3세대 포켓몬 정보는 다음과 같은데 문제점이 있다.
- 문제의 경우에는 파이어레드 버젼이 기준이지만, 본 사이트에는 루비/사파이어 버젼이 우선이다. 큰 차이는 없으나 파이어레드에는 Move Tutor moves같은 스킬도 존재한다.
- 그나마 다행인 점은 JS로 이루어진 것이 아니라 html에 다 포함되어 있기에 selenium같은 툴은 필요가 없다.
- 모든 스킬들은 HTML 상 똑같은 테이블에 똑같은 클래스다. 즉 특정 테이블을 따로가져오기 힘들다.
- HM을 배울 수 없는 포켓몬도 존재한다. (부스터 등등)
- 심지어 TM도 배울 수 없는 포켓몬도 존재한다. (잉어킹, 메타몽 등등)
- 특정 포켓몬에는 Pre-Evolution 스킬이 존재한다.
- 특정 포켓몬에는 Egg moves가 없기도 하다.
그렇기에 다음과 같은 해결방법을 생각했다.
- 거의 같다면 굳이 파이어레드 table을 확인하지 않고, 루비/사파이어 table을 확인한다. 그렇다면 Move Tutor moves을 고려할 필요가 없다.
- 1의 방법으로, 이 문제도 마찬가지로 고려할 필요가 없다.
- 그렇다면 table들을 다 받아 몇 번째 테이블인지를 찾아보자.
- 이 경우 없는 table을 가져와서 에러가 발생한다. 그렇기에 table의 개수에 따라서 예외처리하고, 이 경우 “not learn any HMS”라는 문장이 있기에 이 문장을 찾아서 예외 처리한다.
- 이도 4번과 마찬가지인데 TMs가 아니라 HMs로 되어있다. (사이트 관리자 잘못…) 그렇기에 이 경우에는 위와 같이 문장 개수가 총 6개인 경우를 찾아 예외 처리한다.
- 이유는 HM를 배울 수 있는데 TM을 배우지 못하는 케이스는 없기 때문이다.
- 이 경우에는 후에 table idx+1 해주었다.
- 이 경우에는 후에 table idx-1 해주었다. 이 경우에는 “not learn any moves”라는 문장이 존재한다.
다음과 같은 예외 처리를 한다면 HM과 TM 테이블을 받아올 수 있고, Table 내에 수들은 3의 배수로 이루어져있고, 항상 첫번째 칸이 스킬 번호이므로 idx%3==0일때가 스킬번호고, 이를 저장한다.
각 테이블은 table class = "data-table", 각 숫자는 td class = "cell-num"임을 참고해서 코드를 짜보도록 하자.
다음과 같은 처리는 아래는 소스코드다.
def poke_skill_crawling(sz):
global poke
global poke_skill
for ith in range(0, sz):
URL = "https://pokemondb.net/pokedex/"+ poke[ith] + "/moves/3"
headers = {'User-Agent': 'Mozilla/5.0'} # like web browser
res = requests.get(URL, headers=headers)
bsObj = BeautifulSoup(res.text, "html.parser")
skill_list = bsObj.find_all("table","data-table")
ck = 0
if "not learn any moves" in str(bsObj): # Egg moves check
ck -= 1
if "Pre-evolution" in str(bsObj): # Pre-evolution check
ck += 1
# HM number
HM_list = [0]
# table count
if len(skill_list) >= 3:
# HM check
if str(bsObj).count('not learn any HMs') == 0:
for i in skill_list[2+ck]:
li = i.find_all("td","cell-num")
idx = 0
for j in li:
if idx % 3 == 0:
HM_list.append(j.get_text())
idx+=1
# TM number
TM_list = [0]
if len(skill_list) >= 4:
# TM check
if str(bsObj).count('not learn any HMs') < 6 :
if str(bsObj).count('not learn any HMs') == 3:
ck -= 1
for i in skill_list[3+ck]:
li = i.find_all("td","cell-num")
idx = 0
for j in li:
if idx % 3 == 0:
TM_list.append(j.get_text())
idx+=1
poke_skill.append([HM_list, TM_list])
C. 정보들로 DB table만들기
체크 테이블을 만들고, 각 포켓몬의 정보를 string으로 만들었다. 처음 8개의 문자는 HM, 다음 50개의 문자는 TM을 나타내는 정보이다. 파일 입출력으로 만든다.
def file_making():
global SZ
global poke_skill
f = open('pokemon.txt', 'w', encoding='utf8')
for i in range(0,SZ):
print(i)
hm_ck = [0]*9
for j in poke_skill[i][0]:
hm_ck[int(j)] = 1;
tm_ck = [0]*51
for j in poke_skill[i][1]:
tm_ck[int(j)] = 1;
HM_str, TM_str = "", ""
for j in range(1, 9):
HM_str += str(hm_ck[j])
for j in range(1, 51):
TM_str += str(tm_ck[j])
f.write("\"" + HM_str + TM_str + "\",\n")
f.close()
위의 코드와 위의 코드로 만든 데이터는 다음 링크에 업로드 하였다.
2. 문제 해결 (제출 코드)
DB를 만든 후에는 그냥 입력을 받고, 분류하여 체크하였다. O(58 * 151)의 시간복잡도로 해결할 수 있다.
#include <bits/stdc++.h>
using namespace std;
typedef unsigned long long ull;
typedef pair<int,double> pid;
string arr[151] = {
// data 151*58
};
int main(){
int n; cin >> n;
string ans;
for(int i = 0 ; i < 58 ; i++) ans += '0';
for(int i = 0 ; i < n ; i++){
string tmp; cin >> tmp;
int num = (tmp[2]-'0') * 10+(tmp[3]-'0');
if(tmp[0]=='H'){
ans[num-1] = '1';
}
else{
ans[num+7] = '1';
}
}
for(int i = 0 ; i < 151 ; i++){
int cnt = 0;
for(int j = 0 ; j < 58 ; j++){
if(ans[j]==arr[i][j]&&arr[i][j]=='1') cnt++;
}
if(cnt==n){
cout << i+1 << ' ';
}
}
}

맺음말
예외처리한다고 2번이나 틀리고, 실제 문제를 푸는데 2~3시간 정도 걸린 것 같다. 하나하나 타이핑 하는게 더 빠를 수도 있을듯…
또한 위의 데이터는 58byte문자열로 DB를 넘겨주었는데, 이는 0,1로만 이루어져있으니 long long으로 처리해서 넘겨줄 수도 있다. 하지만 거기까지는 귀찮아서 처리하지 않았다.
다음 코드는 아래 링크에 있다.
출처 : BOJ 문제에 대한 모든 권리는 BOJ(acmicpc.net, startlink)에 있음
Leave a Comment