
Part 1. What is Ensemble Learning?
0. Intro
머신러닝 튜토리얼에 Advanced 알고리즘을 보면 항상 앙상블 학습이라는 내용이 포함되어 있습니다. 최근 캐글 우승자의 인터뷰를 보면 대다수가 앙상블 기법 중 하나를 이용했다고 합니다.
이는 앙상블을 알아야 캐글에서 좋은 성적을 받을 수 있다는 말이기도 합니다.
앙상블 알고리즘에 대해 포스팅은 3개 정도로 나누어 올리겠습니다. 예상으로는 다음과 같이 나눌 수 있을 것 같습니다.
- Part 1. What is Ensemble Learning
- Part 2. Voting & Bagging with Code
- Part 3. Boosting with Code
- Part 4. Stacking with Code
(포스팅을 적으며 목록을 수정했습니다.)
첫 번째 포스팅은 종류와 개념에 대해 다뤄보겠습니다. 구체적인 방법에 대한 내용은 다음 포스팅에서 다루겠습니다.
1. What is Ensemble Learning?

앙상블(Ensemble) 학습은 여러 개의 학습 알고리즘을 사용하고, 그 예측을 결합함으로써 보다 정확한 최종 예측을 도출하는 기법입니다. 하나의 강한 머신러닝 알고리즘보다 여러 개의 약한 머신러닝 알고리즘이 낫다 라는 아이디어를 가지고 이해하면 좋습니다.
이미지, 영상, 음성 등의 비정형 데이터의 분류는 딥러닝이 뛰어난 성능을 보이고 있지만, 대부분의 정형 데이터 분류 시에는 앙상블이 뛰어난 성능을 나타내고 있습니다.
문제와 데이터에 따라 단일 모델의 성능이 더 좋은 경우도 있습니다. 하지만 앙상블 기법을 사용하면 더 유연성있는 모델을 만들며 더 좋은 예측 결과를 기대할 수 있습니다.
캐글에서는 높은 성적을 얻기 위해서 시도해볼 수 있는 테크닉 중 하나이며, 최근 많은 winning solution에서 앙상블 기법이 사용되었습니다.
앙상블 학습의 유형은 가장 많이 알려진 Voting, Bagging, Boosting, Stacking 등이 있으며, 그 외에도 다양한 앙상블 학습의 유형이 있습니다.
2. Voting & Averaging

보팅(Voting) 또는 에버리징(Averaging) 은 가장 쉬운 앙상블 기법입니다. 이 둘은 서로 다른 알고리즘을 가진 분류기를 결합하는 방식입니다. Voting은 분류 에서 사용하며 Averaging은 회귀 에서 사용합니다. (categorical인 경우에는 voting, numerical인 경우에는 averaging이기도 합니다.)
단어 그대로 투표, 평균의 방식으로 진행이 됩니다. 좀 더 구체적으로 서술하면 다음과 같은 과정으로 진행이 됩니다.
- 일정 수의 base model과 predict를 만듭니다.
- 1-1. 훈련 데이터를 나누어 같은 알고리즘을 사용하거나
- 1-2. 훈련 데이터는 같지만 다른 알고리즘을 사용하거나
- 1-3. 등등의 방법을 사용합니다.
- 여기서 여러가지 방법으로 voting을 진행합니다.
base model은 Linear Regression, KNN, SVM 등 여러 머신러닝 모델을 사용하면 됩니다. Voting과 Averaging은 다음과 같은 분류로 나눌 수 있습니다.
2-1. Majority Voting (Hard Voting)
각 모델은 test 데이터셋(또는 인스턴스)의 결과를 예측합니다. 그리고 예측값들의 다수결로 예측값을 정합니다. 이진 분류에 있어서는 과반수 이상이 선택한 예측값을 최종 예측으로 선택하는 것입니다.
이런 다수결의 성격때문에 max voting, plurality voting 라고도 부릅니다.
2-2. Weighted Voting (Soft Voting)
위의 보팅 방법과 다르게, 좀 더 유연한 보팅 방법입니다.
이번에는 test 데이터셋(또는 인스턴스)의 결과 가능성을 예측합니다. 그리고 이 가능성(가중치)를 특정 연산을 하여 분류 label의 확률값을 계산합니다. 이 방법에서 가중치의 연산은 원하는 방식으로 할 수 있고, 보통 평균을 사용합니다.
보통 Majority Voting보다 유연한 결과를 얻을 수 있으며, 예측 성능이 좋아 더 많이 사용합니다.
2-3. Simple Averaging
회귀 문제에서 사용하는 방법으로, 각 예측값을 평균내어 사용합니다. 이 방법은 경우에 따라 과대적합을 줄여주고, 더 부드러운 회귀모델을 만들어줍니다.
2-4. Weighted Averaging
위에서 평균을 낼 때, 각 모델별 가중치를 두어 평균내는 방식입니다.
3. Bagging

배깅(Bagging) 은 Bootstrap Aggregating의 약자입니다. 배깅의 핵심은 평균을 통해 분산(variance)값을 줄여 모델을 더 일반화시킨다는 점입니다.
배깅은 보팅과 유사한 방식으로 진행이 됩니다. 정확히는 최종적으로는 보팅을 사용합니다.
- 일정 수의 base model을 만듭니다.
- 모델들의 알고리즘은 모두 같습니다.
- 각각의 모델은 훈련데이터셋에서 랜덤으로 만든 서브 데이터셋을 각각 사용합니다.
3에서 서브 데이터셋을 만드는 과정을 부트스트래핑(Bootstrapping) 분할 방식이라고 합니다. 각각의 서브 데이터셋은 중첩이 가능합니다. 즉 다음과 같은 식이 만족될 수 있습니다.
\[S_{tot} \neq S_1 \cup S_2 \cup \cdots \cup S_k\]배깅의 경우에는 데이터 생성과 훈련이 개별 모델에서 진행되므로, 병렬 연산이 가능합니다.
배깅의 대표적인 알고리즘은 랜덤 포레스트(Random Forest) 입니다. 그 외에도 Bagging meta-estimator가 있습니다.
3-1. Bagging meta-estimator
Bagging meta-estimator는 랜덤 포레스트의 모체가 되는 알고리즘입니다. 위에서 언급한 방식을 그대로 사용하는 알고리즘입니다.
3-2. Random Forest
랜덤 포레스트 알고리즘은 여러 결정 트리(Decision Tree) 를 사용하여 보팅(soft voting)을 통해 예측을 결정하는 것입니다.
Bagging meta-estimator과 다르게 결정트리만 사용하고, 특성(feature)을 랜덤으로 선택하여 Bagging을 진행한다는 점이 다릅니다.
tree가 모여 forest라니 너무 귀엽지 않나요 :-)
결정 트리의 경우, 쉽고 직관적인 성격때문에 다른 앙상블 알고리즘에서도 많이 채택하고 있습니다. 랜덤 포레스트는 앙상블 알고리즘 중 비교적 빠른 속도를 가지고 있으며, 다양한 분야에서 좋은 성능을 낸다는 점에서 매우 장점이 많은 알고리즘입니다.
단점은 트리 기반의 앙상블 알고리즘은 하이퍼파라미터가 많아 튜닝을 위한 시간이 많이 소모된다는 것입니다. (속도 자체는 다른 알고리즘에 비해 빠릅니다.) 또한 하이퍼파라미터의 조정을 통한 성능의 향상이 비교적 미비하다는 단점을 가지고 있습니다.
4. Boosting
부스팅(Boosting) 알고리즘은 여러 개의 약한 학습기(weak learner)를 순차적으로 학습-예측하며 잘못 예측한 데이터에 가중치 부여를 통해 오류를 개선해 나가면서 학습하는 방식입니다.
계속해서 분류기에게 가중치를 부스팅하면서 학습을 진행하기에 부스팅 방식으로 불립니다.
기존 Boosting 방법은 순차적인 연산이 필수적이므로 병렬 연산이 불가능합니다. 그렇기에 대용량 데이터셋에서는 학습 시간이 매우 많이 필요할 수 있습니다.
부스팅의 대표적인 알고리즘은 AdaBoost 와 Gradient Boost 가 있고, 최근 성능면에서 인정을 받아 가장 많이 사용하는 부스팅 계열 알고리즘으로 XGBoost 와 LightGBM 이 있습니다. 그 외에도 CatBoost와 같은 알고리즘이 있습니다.
4-1. AdaBoost
에이다 부스트(AdaBoost) 는 Adaptive boosting의 약자로 오류 데이터에 가중치를 부여하며 부스팅을 수행하는 대표적인 알고리즘입니다.
메인 아이디어는 잘못 분류한 데이터에 가중치를 부여하여, 다음 분류기는 이를 더 잘 분류하게 만드는 것입니다. 최종적으로는 이 분류기를 합쳐 최종 분류기를 만듭니다. (분류 문제에 대하여)
오류 데이터에 가중치를 부여하기 때문에 이상치(outlier)에 민감합니다.
4-2. Gradient Boost
그래디언트 부스트(Gradient Boost Machine) 알고리즘은 AdaBoost와 거의 유사합니다. 하지만 가중치 업데이트를 경사하강법(Gradient Descent) 로 한다는 점이 다릅니다.
평균적으로 랜덤 포레스트보다 좋은 예측 성능을 가지지만, 하이퍼파라미터 튜닝 노력이 필요하고 그만큼 수행 시간이 오래걸린다는 단점도 있습니다. 순차적인 진행때문에 병렬 수행이 불가능하다는 단점도 있습니다. 성능면에 초점을 두어 많은 GBM 기반 알고리즘이 연구되었고, 그 중 가장 많이 사용하는 것이 아래 두 알고리즘입니다.
4-3. XGBoost
XGBoost(eXtra Gradient Boost) 는 GBM에 기반하는 알고리즘이며, 여러 가지 장점을 가진 알고리즘입니다. GBM에 비해 빠르고, 과적합 규제 등의 장점을 가집니다. 그 외에도 분류/회귀 모두 예측 성능이 우수하고, 자체 내장 교차 검증, 결손값 처리 등의 장점이 있습니다.
병렬 CPU를 이용하여 GBM보다 빠른 수행을 합니다. 반대로 말하면 속도를 기대하려면 multi-CPU core가 필요합니다. 이 외에도 tree pruning 등의 다양한 기능을 통해 속도를 향상시켰습니다.
XGBoost는 GBM보다는 빠르지만 여전히 느린 알고리즘입니다. 심지어 GridSearchCV를 이용하여 하이퍼파라미터 튜닝을 수행하면 시간이 너무 오래 걸립니다.
4-4. LightGBM
LightGBM 은 이름에서 알 수 있듯이 Light한 GBM입니다.
XGBoost에 비해 훨씬 빠르며, 메모리 사용량도 상대적으로 적습니다. 예측 성능 자체도 큰 차이는 없습니다. 하지만 적은 수의 데이터셋에는 과대적합이 발생하기 쉽다는 단점이 있습니다. 적다는 기준은 애매하나 공식 문서에는 10000건 이하의 데이터셋이라고 기술하고 있습니다.
알고리즘의 메인 아이디어는 GBM 계열의 트리 분할 방법에서 트리 균형 맞추는 과정을 생략하며 성능을 높였다는 점입니다. 대부분의 트리 기반 알고리즘은 트리의 깊이를 효과적으로 줄이기 위해 균형 트리 분할(Level Wise) 방식을 사용합니다. 균형 잡힌 트리는 과대적합에 강하지만 시간 비용이 큽니다.
LightGBM에서는 리프 중심 트리 분할(Leaf Wise) 방식을 사용해 비대칭이지만 예측 오류 손실 값을 줄이는 방식을 선택하여 트리를 분할합니다. 그렇기에 빠르고, 좋은 성능을 가질 수 있는 것입니다.
4-5. CatBoost
CatBoost 는 범주형 변수를 위해 만든 Boosting 알고리즘입니다. 범주형 변수의 경우에는 원-핫 인코딩을 할 경우에 많은 수의 특성이 생기기에 부스팅 알고리즘을 사용하는 경우, 매우 오랜 시간이 걸립니다. 그렇기에 범주형 변수를 자동으로 처리하기 위해 만든 알고리즘입니다.
아직 경험이 부족해서 사용하는 컴페티션을 본 적은 없습니다.
5. Stacking & Blending
Stacking과 Blending은 거의 같지만, 분류하는 경우도 있어 따로 서술했습니다.
5-1. Stacking (Stacked generalization)
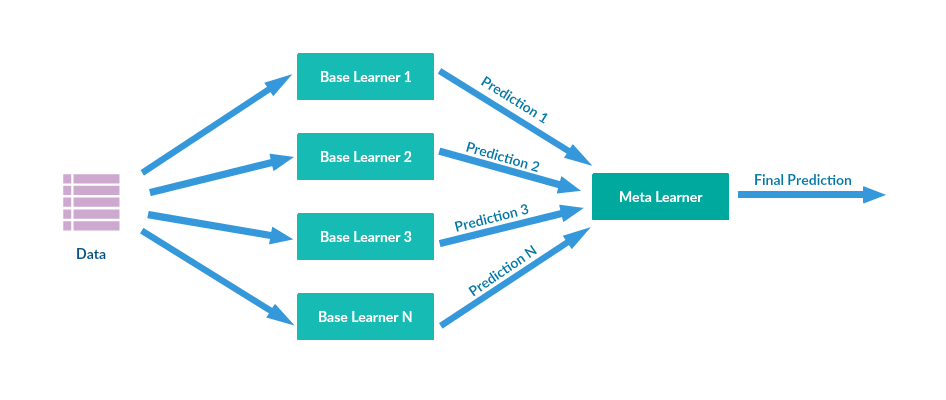
스태킹(Stacking) 또는 stacked generalization으로 알려진 기법입니다.
현실 모델에 적용하는 경우는 적으나, 대회에서 높은 순위를 위해 많이 사용됩니다.
가장 핵심 아이디어는 머신러닝 알고리즘으로 훈련 데이터셋을 통해 새로운 데이터셋을 만들고, 이를 데이터셋으로 사용하여 다시 머신러닝 알고리즘을 돌리는 것입니다. 보통은 서로 다른 타입의 모델들 을 결합합니다.
스태킹에는 총 2가지 종류의 모델이 필요합니다.
- 개별적인 기반 모델 : 성능이 비슷한 여러 개의 모델
- 최종 메타 모델 : 기반 모델이 만든 예측 데이터를 학습 데이터로 사용할 최종 모델
다시 정리해서 말하면 여러 개의 개별 모델들이 생성한 예측 데이터를 기반으로 최종 메타 모델이 학습할 별도의 학습 데이터 세트와 예측할 테스트 데이터 세트를 재 생성하는 기법입니다.
모델을 통해 input을 만들고, 다시 모델에 넣는 구조때문에 meta-model 이라고도 부릅니다.
Stacking에는 다양한 유형이 있고, 내용 자체가 직관적으로 이해하기 힘듭니다. 이 부분에 대해 자세한 내용은 2부에 다루겠습니다.
5-2. Blending
Blending 은 스태킹과 매우 유사한 방법입니다. 하지만 보다 간단하고, 정보누설의 위험을 줄입니다. 일부는 Stacking과 Blending을 혼용해서 사용합니다. (대부분은 스태킹과 같은 의미로 사용하는 것 같습니다.)
과정 자체는 거의 같습니다. 차이점이 있다면 Stacking에서는 cross-fold-validation을 사용하고, Blending은 holdout validation을 사용합니다.
그렇기 때문에 Blending의 결과는 holdout set에 과대적합이 된 결과를 얻을 가능성이 높습니다.
6. Conclusion
결과를 높이기에는 좋은 방법이지만, 해석 가능성을 낮추는 방법이기도 합니다. 그렇기에 과정을 중시하는 곳에서는 선호하지 않는 방법입니다.
하지만 컴페티션에 있어서는 정확도가 높다는 것은 매우 중요합니다. 캐글을 해보신 분이라면 0.1%의 정확도 향상도 얼마나 대단한 것인지 아실겁니다. 또한 의료 분야 등 정확도가 반드시 높아야 하는 경우에는 필요합니다. 과정보다는 결과가 중요한 곳이 있기 때문입니다.
다음 포스팅에서는 분야별로 구체적인 내용에 대해서 다뤄보겠습니다. Part2에서 뵙겠습니다. :-)
Reference
세상에는 좋은 자료가 너무 많습니다. 시간이 된다면 아래 링크와 책 모두 읽는 것을 추천합니다.
Leave a Comment