
Missing Data는 어떻게 관리할 수 있을까요? Handling을 해봅시다!!
왜 생기는걸까? : 완벽하지 않은 세상!
Missing Data는 표현 그대로 측정하고, 저장한 데이터의 일부가 누락된 것을 의미합니다. 저는 앞으로 누락 과 결측값 으로 이 단어가 가지는 의미를 표현하도록 하겠습니다. 이런 결측값은 때로는 Model의 훈련을 막기도 하며, 결과값에 어떤 방식으로든 영향을 미치기 때문에 ML에 있어 핵심 부분이기도 합니다.
흔히 말하는 real world에서 관측하는 대부분의 데이터는 missing data가 있기 때문 이를 관리하는 능력은 반드시 필요합니다. 우선 생기는 이유를 먼저 보도록 하겠습니다.
결측값이 생기는 큰 이유는 다음과 같습니다.
1. Missing Completely at Random (MCAR)
- 정말 랜덤하게 누락된 케이스
- 변수의 종류와 상관없이 전체적으로 비슷하게 누락된 데이터입니다.
- 통계적으로 확인가능한 missing pattern
2. Missing at Random (MAR)
- Missing Conditionally at Random 이라고도 함
- 어떤 특정 변수에 관련하여 자료가 누락된 케이스
- 결측값이 자료 내의 다른 변수와 관련되어 있는 경우
- ex) 어떤 설문조사에서 일부 대상자가 설문지 반대쪽 면 이 있는 것을 모르고 채우지 않았을 경우
3. Missing not at Random (MNAR)
- 어떤 특정 변수에 관련하여 자료가 누락된 케이스
- 결측값이 해당 변수와 연관이 있는 경우
- ex) 어떤 설문조사에서 일부 질문에 정치적인 성향 등의 이유로 채우지 않았을 경우
앞의 두 가지는 결측값을 제거하는 것이 좋습니다. 하지만 MNAR의 경우는 결측값이 있는 데이터를 지운다면? 모델이 편향될 가능성이 커지고, 일반화된 모델을 구하기 어려워질 것입니다. 그렇기 때문에 데이터를 지울 것인가, 다시 채워넣을 것인가는 이런 결측값이 생기는 이유를 고려하여 진행해야 합니다.
Python Pandas에서 결측값은
None또는NaN이 있으니 알아둡시다!
어떤 해결 방법이 있을까요?
어떤 합리적인 이유라도 누락된 값에 대한 확실한 답안을 내놓을 수 없습니다. (세상 모든 일에 100%란 없는거니까요~) 위키에 따르면 일반적인 접근 방법에는 3가지가 있다고 합니다.
- Imputation : 누락된 데이터 대신 값을 채우는 방법
- Deletion(omission) : 분명하지 않은 결측값이 있는 데이터를 제거(생략)하는 방법
- Analysis : 누락된 데이터를 사용하지 않는 방법
(위키에서 말하는 analysis가 무슨 말인지 몰라서) 핵심인 Imputation과 Deletion을 위주로 보도록 하겠습니다.
Deletion : 살릴 수 없는 데이터는 버리자
제거는 단순합니다. 총 3가지 방법에 대해서 살펴봅시다.
- Listwise
- Dropping
- Pairwise
Listwise Deletion : 결측값이 있다면 그 데이터는 버리는 방법
아마 가장 쉬운 방법은 missing data가 있는 데이터를 지우는 방법입니다. MNAR의 경우에는 모델이 편향될 가능성이 있으므로 주의해서 사용해야 합니다.
pandas에서는 다음과 같습니다.
# df는 Pandas의 DataFrame 객체의 가상 이름입니다.
df.dropna() # 결측값이 있는 데이터 삭제
df.dropna(how='all') # 데이터의 모든 값이 Missing Value인 경우
df.drop(index, axis=0) # 배열 또는 단일 정수로 주어진 index 모두 제거
Dropping Variable : 특정 변수가 지나치게 비어있다면 변수를 버리는 방법
Listwise Deletion과 유사한 방법으로는 해당 변수(피처) 자체를 지우는 방법이 있습니다. 우리가 삭제하고자 하는 피처가 유용한 피처인지 모르기에 함부로 지워서는 안됩니다. 하지만 70~80%가 비어 있는 변수라면 분석하기 어렵고, 이를 사용하기도 어렵기에 지우는 게 나을 수 있습니다.
df.dropna(axis='columns') # 결측값이 있는 피처 컬럼 모두 삭제
df.drop('column_name', axis=1)
drop 등 pandas에서
inplace=True라는 매개변수를 많이 볼 수 있는데, 이는 객체 자체를 변화시키는 코드입니다.inplace=False시 새로운 dataframe 객체를 생성하는 것이므로 대입 등으로 이를 저장해야합니다.
Pairwise Deletion : 필요에 따라 사용하는 방법
이 방법은 특별한 기법은 아닙니다. 한마디로 필요한 경우에 따라서 데이터를 선별하자는 것입니다. A의 케이스에서는 [2, 3] row를 사용하지 않고, B의 케이스에서는 [3, 4] row를 사용하지 않는 등 원하는 방식으로 데이터를 사용하는 것입니다. 여기서는 누락하는 데이터가 MCAR이라고 가정합니다.
다만 이렇게 진행하게 된다면, 서로 다른 부분읠 관측한 통계값을 사용하게 되므로 해석이 어려워질 수 있다는 단점이 있습니다.
Imputation : 인사이트와 통계로 데이터를 채우자
Mean, Median, Mode : 대표값을 사용하자
Mean은 평균, Median은 중앙값, Mode는 최빈값을 의미합니다. R에서 다음과 같이 매개변수가 있어 표현을 하였습니다. 데이터의 유형에 따라 값을 선택하면 됩니다.
이런 대표값을 사용하는 방법은 매우 빠르다 는 장점이 있지만, 다음과 같은 여러 단점을 가지고 있습니다.
- 다른 피처간의 상관도를 전혀 고려하지 않는다.
- 비슷한 느낌으로 경향성에 대한 고려가 없다.
- 정확도가 떨어진다.
- 평균의 경우, 분산이 줄어든다.
- 최빈값의 경우, 데이터 전체에 편향이 생긴다.
sklearn의 sklearn.impute.SimpleImputer를 사용할 수 있습니다.
from sklearn.impute import SimpleImputer
imp_mean = SimpleImputer( strategy='most_frequent') # mean, median
imp_mean.fit(train)
imputed_train_df = imp_mean.transform(train)
데이터 사이언티스트의 인사이트에 따라 대표값으로 0 또는 다른 상수값을 사용할 수 있습니다.
Multiple Imputation(MI) : 좋은 거 + 좋은 거 = 좋은 거
Imputation으로 인한 노이즈 증가 문제를 해결하기 위한 방법입니다. 단순하게 한 번 Imputation을 진행한 것보다 여러 Imputation을 조합하는 것이 더 좋다는 아이디어입니다. 모든 MI는 3가지 과정을 거칩니다.
- Imputation : distribution을 토대로 m개의 데이터셋을 imputation합니다. 이 과정에서 Markov Chain Monte Carlo (MCMC)를 사용하면 더 나은 결과를 얻을 수 있다고 합니다.
- Analysis : m개의 완성된 데이터셋을 분석합니다.
- Pooling : 평균, 분산, 신뢰 구간을 계산하여 결과를 합칩니다.
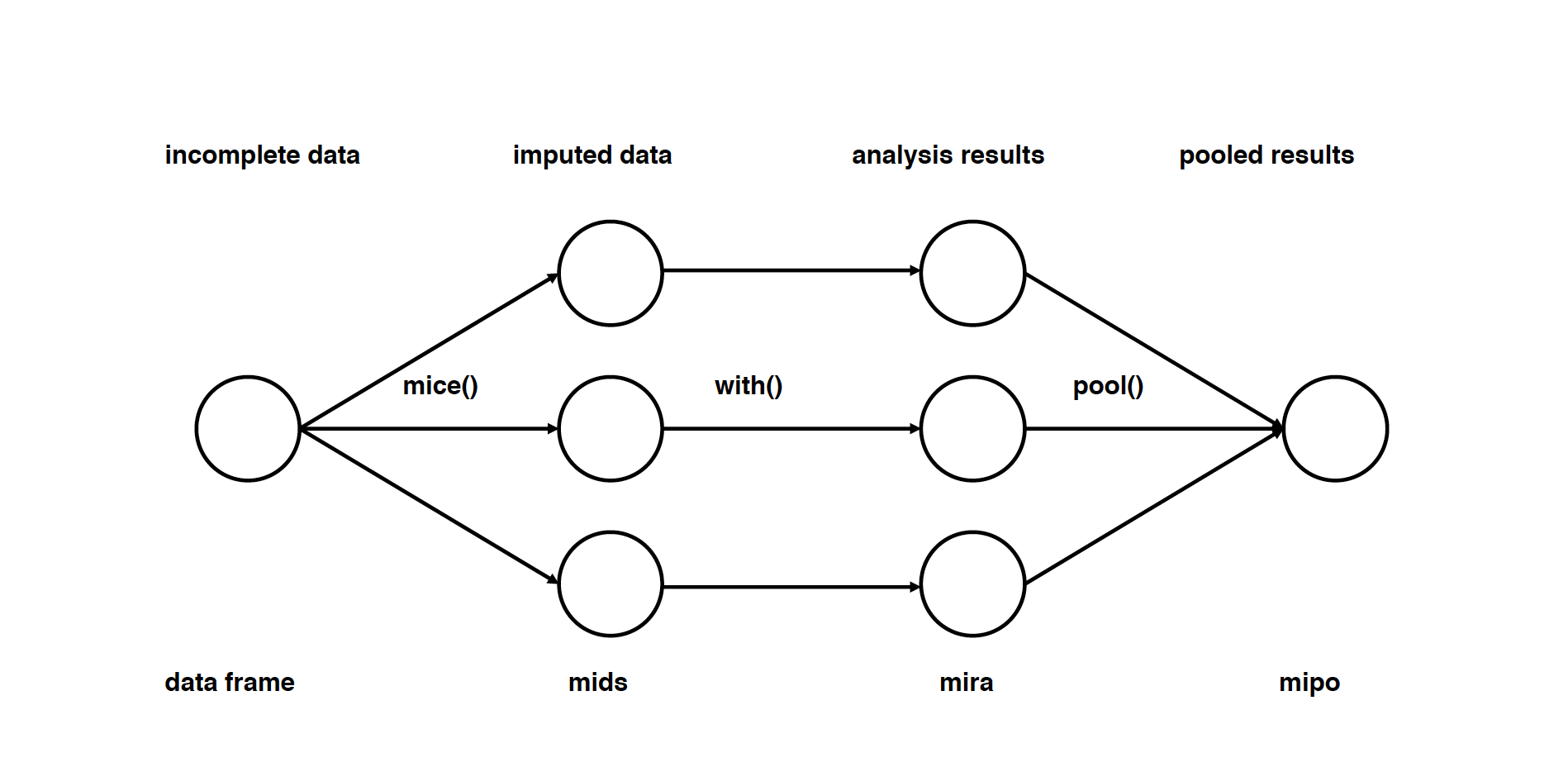
MI는 위의 누락 이유와 상관없이 사용할 수 있습니다. MI도 여러가지 방법이 있지만, 그 중에서 가장 우선이 되는 방법은 multiple imputation by chained equations (MICE) 입니다. 다른 이름으로는 fully conditional specification 과 sequential regression multiple imputation 이 있습니다.
from impyute.imputation.cs import mice
# start the MICE training
imputed_training=mice(train.values)
KNN (K-Nearest Neighbors) : ML을 위한 ML
ML의 기본적인 알고리즘 중 하나인 KNN을 사용하는 방법도 있습니다. KNN은 본인과 가까운 K개의 데이터를 선택하여, 그 평균을 취하는 방식입니다.
mean, mode 등에 비해 비교적 정확하다는 장점이 있지만, KNN이 가지는 단점을 그대로 가져옵니다.
- 계산량이 많다.
- outlier에 민감하다.
- feature의 scale이 중요하다. (유클리드 or 맨허튼 거리를 기반으로 하기때문에)
- 고차원 데이터에서 매우 부정확할 수 있다.
코드는 다음과 같습니다.
from fancyimpute import KNN
knnOutput = KNN(k=5).complete(mydata) # k값으로 이웃값 조정
좋은 알고리즘을 사용하자
좋은 방법 중 하나는 이것들을 고려하지 않는 좋은 알고리즘을 사용하는 것입니다. Boost 계열의 알고리즘은 이런 결측값이 있어도 잘 예측하니 이 방법에 대해 좀 더 공부해보는 것도 추천합니다.
- XGBoost
- LightGBM
- CatBoost
최근 캐글 winning solution의 다수에 포함되어 있으니 한 번쯤 공부해보는 것도 좋겠죠? 가볍게 개념을 알고 싶은 분들은 제 앙상블 정리 글을 추천합니다.
Reference & Wrapped Up
- ML을 공부하다보면 R에는 참 다양한 패키지가 있고, Python이 열심히 이를 만들고 있는 것 같습니다. 시간이 된다면 R도 공부하면 재밌을 것 같습니다.
- 조만간 부스트 계열 알고리즘 정리 글을 업로드하도록 하겠습니다. 기대해주세요 :-)
- 나만 몰랐던 라이브러리를 시리즈로 만들면 재밌겠다는 생각을 합니다. 이번에는 impyute입니다.
-
위키글에 좋은게 많습니다. 읽어보는 것을 추천합니다.
- How to Handle Missing Data
- 6 Different Ways to Compensate for Missing Values In a Dataset (Data Imputation with examples)
- Wikipedia : Missing Data
- Wikipedia : Imputation
- R강의7. 누락된 자료의 처리
- Handling Missing Data
- How to Handle Missing Data with Python
Leave a Comment