
Top 8 trends from ICLR 2019 번역글
Intro
ICLR 2019의 트렌드를 분석한 글입니다. 원 저자의 동의 하에 번역하여 공유합니다. 원 저자인 Chip Huyen님과 Oleksii Hrinchuk님에게 감사의 인사를 남깁니다. 저자 개인의 의견이 포함되어 있는 글입니다.
원문은 다음 링크를 참고해주세요.
- Inclusivity
- Unsupervised representation learning & transfer learning
- Retro ML
- RNN is losing its luster with researchers
- GANs are still going on strong
- The lack of biologically inspired deep learning
- Reinforcement learning is still the most popular topic by submissions
- Most accepted papers will be quickly forgotten
1. Inclusivity
역자의 말 저는 이 단어가 너무 생소하여 찾아봤습니다. 이 단어는 “the fact or policy of not excluding members or participants on the grounds of gender, race, class, sexuality, disability, etc” 라는 뜻으로 회원 또는 참가자들을 성, 인종, 계층, 성, 장애 등의 이유로 차별하지 않는 사실 또는 정책 을 의미합니다. 번역에서는 단어를 번역하지않고 사용합니다.
주최측은 처음 두 가지 주요 회담이 fariness와 equility에 관한 것인지 확인함으로써 AI 분야에서 Inclusivity의 중요성을 강조했습니다.
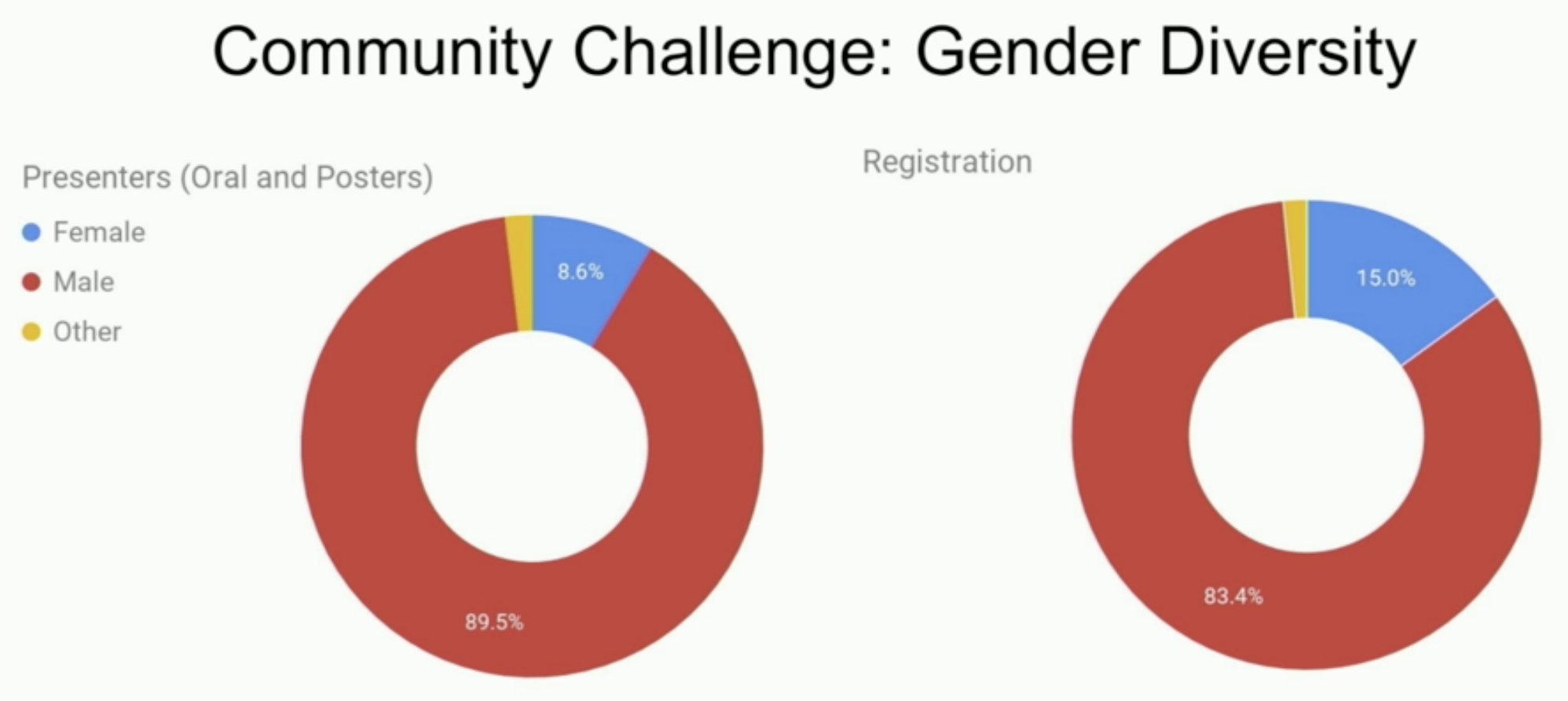
일부 걱정스러운 통계는 다음과 같습니다.
- 8.6%의 발표자, 15%의 참가자만이 여성입니다.
- 모든 LGBTQ+ 연구원 중 2/3는 전문적이지 않습니다.
- 초대된 8명의 연사는 모두 백인입니다.
안타깝게도 평균적인 AI 연구원들은 이 문제에 대해 무관심한 것 같습니다. Social Good 분야 워크숍은 Yoshua Bengio 전까지 다른 워크숍에 비해 거의 비어있었습니다.
작성자 분의 경험에 의하면 ICLR에 참석하여 했던 수많은 대화 중에 1번의 대화를 제외하고는 이런 문제에 대해서는 이야기가 나오지 않았습니다. 또한 그 대화 또한 작성자가 왜 어울리지 않는 기술 행사에 참여했냐는 말이 었다고 합니다. 어떤 분은 이런 말도 했습니다.
“공격적인 대답은 당신이 여자이기 때문입니다.”
이런 무관심에 대한 이유는 다음과 같습니다.
-
이런 논의가 “기술”과 관련이 없기 때문입니다. 이런 주제는 개인의 연구 경력을 향상 시키는데 도움이 되지 않는다는 것입니다.
-
사회 옹호에 반대하는 분들이 아직 많습니다. 어떤 분은 그룹 채팅에서 “평등과 다양성으로 상대방을 괴롭히니 나(작성자)와 함께 다니는 친구를 무시하라”고 말했다고 합니다.
2. Unsupervised representation learning & transfer learning
비지도 학습의 주요 목표는 레이블이 지정되지 않은 데이터에서 유용한 데이터 표현을 발견하여 후속 작업에 사용하는 것입니다. 자연어 처리에서 비지도 학습은 종종 언어 모델링(language modeling)에 사용됩니다. 학습된 표현은 감정 분석(sentiment analysis), 개체명 인식(named entity recognition), 기계 번역(machine translation)같은 문제에 사용됩니다.
작년에 나온 흥미로운 논문에 다음과 같습니다.
- ELMo (Peters et al.)
- ULMFiT (Howard et al.)
- OpenAI’s GPT (Radford et al.)
- BERT (Devlin et al.)
- GPT-2 (Radford et al.)
Full GPT-2는 ICLR에서 데모되었으며 상당히 좋았습니다. 거의 모든 프롬프트를 입력할 수 있으며, 이는 나머지 글을 작성하였습니다. 이는 buzzfeed 기사, 팬픽, 과학 문서, 심지어 만들어낸 단어의 정의까지 작성할 수 있었습니다. 하지만 아직 완벽하게 인간같지는 않았습니다. 이 팀은 더 크고 좋은 성능을 위해 GPT-3를 연구하고 있고, 저는 이를 매우 기대하고 있습니다.
컴퓨터 비전 분야는 처음으로 transfer learning을 사용하였지만, 아직까지 기본 작업은 지도학습입니다. 아직도 양쪽 분야(자연어 처리, 컴퓨터 비전) 연구자가 계속 듣는 질문은 다음과 같습니다.
“어떻게 이미지에서 비지도 학습을 적용할수 있을까?”
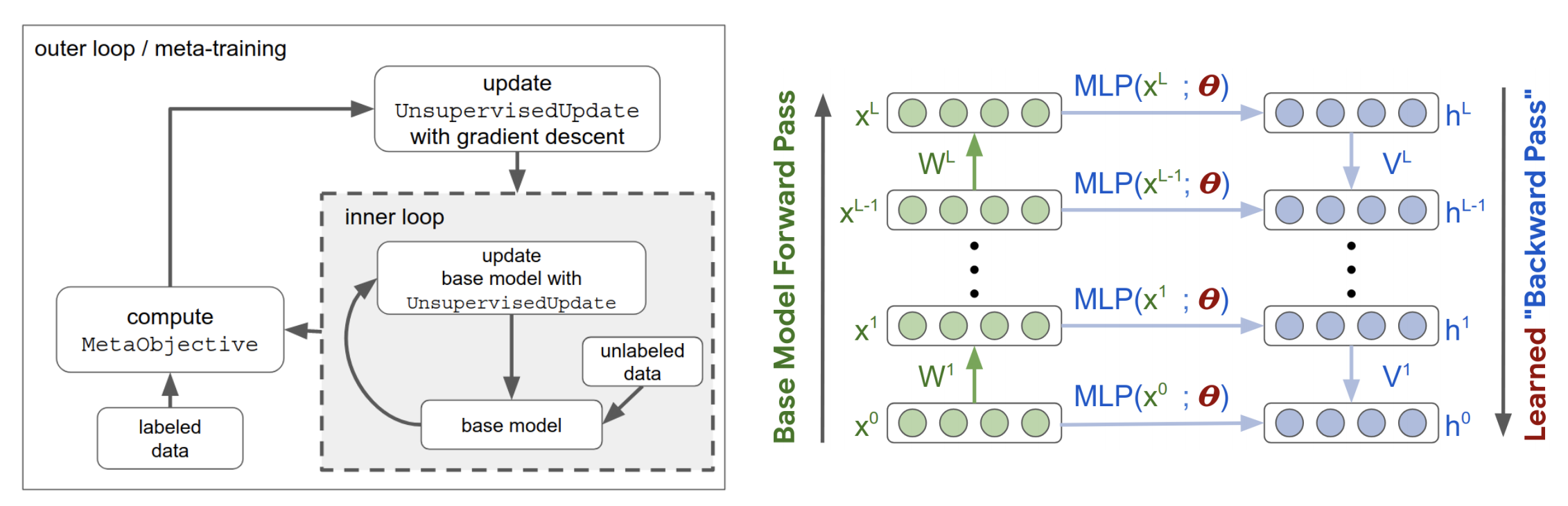
이에 대해 많은 연구가 이뤄지고 있지만, ICLR에 발표된 논문은 “Meta-Learning Update Rules for Unsupervised Representation Learning” (Metz et al.) 하나였습니다. 가중치를 업데이트하는대신 알고리즘이 학습 규칙을 업데이트합니다. 학습 규칙에서 배운 표현은 이미지 분류 작업을 위해 적은 수의 분류된 샘플에서 미세 조정됩니다. 이런 과정으로 이들은 MNIST와 Fashion MNIST에서 70% 이상의 정확도를 가지는 학습 규칙을 찾을 수 있었습니다.
작성자는 코드의 전체가 아닌 일부를 공개하였고, “계산에 연결되어 있기 때문”이라고 합니다. 외부 루프는 총 100,000개의 훈련 단계와 256개의 CPU에서 200시간을 필요로 합니다.
가까운 장래에 이와 같은 논문을 많이 보게 될 것이라고 생각합니다. 비지도 학습이 필요한 분야로 오토인코딩(autoencoding), 이미지 회전 예측(predicting image rotations ICLR 2018에서 핫했던 논문), 비디오의 다음 프레임 예측 등이 있습니다.
3. Retro ML
기계학습은 패션과 유사합니다. 계속 돌고 도는 거죠.
MIT Media Lab의 Grounded Language Learning and Understanding 프로젝트는 2001년에 중단되었지만 올해는 강화학습이라는 옷을 입고 2개의 논문으로 컴백했습니다.
- DOM-Q-NET: Grounded RL on Structured Language (Jia et al.) : 자연어로 설정된 목표에서 링크를 클릭하고 웹을 탐색하여 필드를 채우는 강화학습 알고리즘
- BabyAI: A Platform to Study the Sample Efficiency of Grounded Language Learning (Chevalier-Boisvert et al.) : agent가 합성 언어를 학습하게 도와주는 (인간) 교사를 시뮬레이트하는 agent 봇을 포함한 OpenAI Gym에 호환 가능 플랫폼
이 두 논문에 대한 본인의 견해는 AnonReviewer4에 의해 완벽하게 요약되어있습니다.
“… 제안된 방법들은 semantic parsing literature에서 꽤 오랫동안 연구된 방법과 매우 유사합니다. 그러나 이 논문은 deep RL 논문만을 인용하고 있습니다. 저자는 기존의 문헌을 익히는 것이 큰 도움이 될 것이라고 생각합니다. semantic parsing 분야에서도 이 논문은 도움이 될 것이라고 생각합니다. 하지만 두 커뮤니티는 그들이 비슷한 문제를 해결하는데에 반해 어떠한 말도 서로에게 하지 않고 있습니다. “
Deterministic Finite Automata(DFA)도 이번에 딥러닝 세계에서 두 논문과 함께 자리를 잡았습니다.
- Representing Formal Languages: A Comparison Between Finite Automata and Recurrent Neural Networks (Michalenko et al.)
- Learning Finite State Representations of Recurrent Policy Networks (Koul et al.)
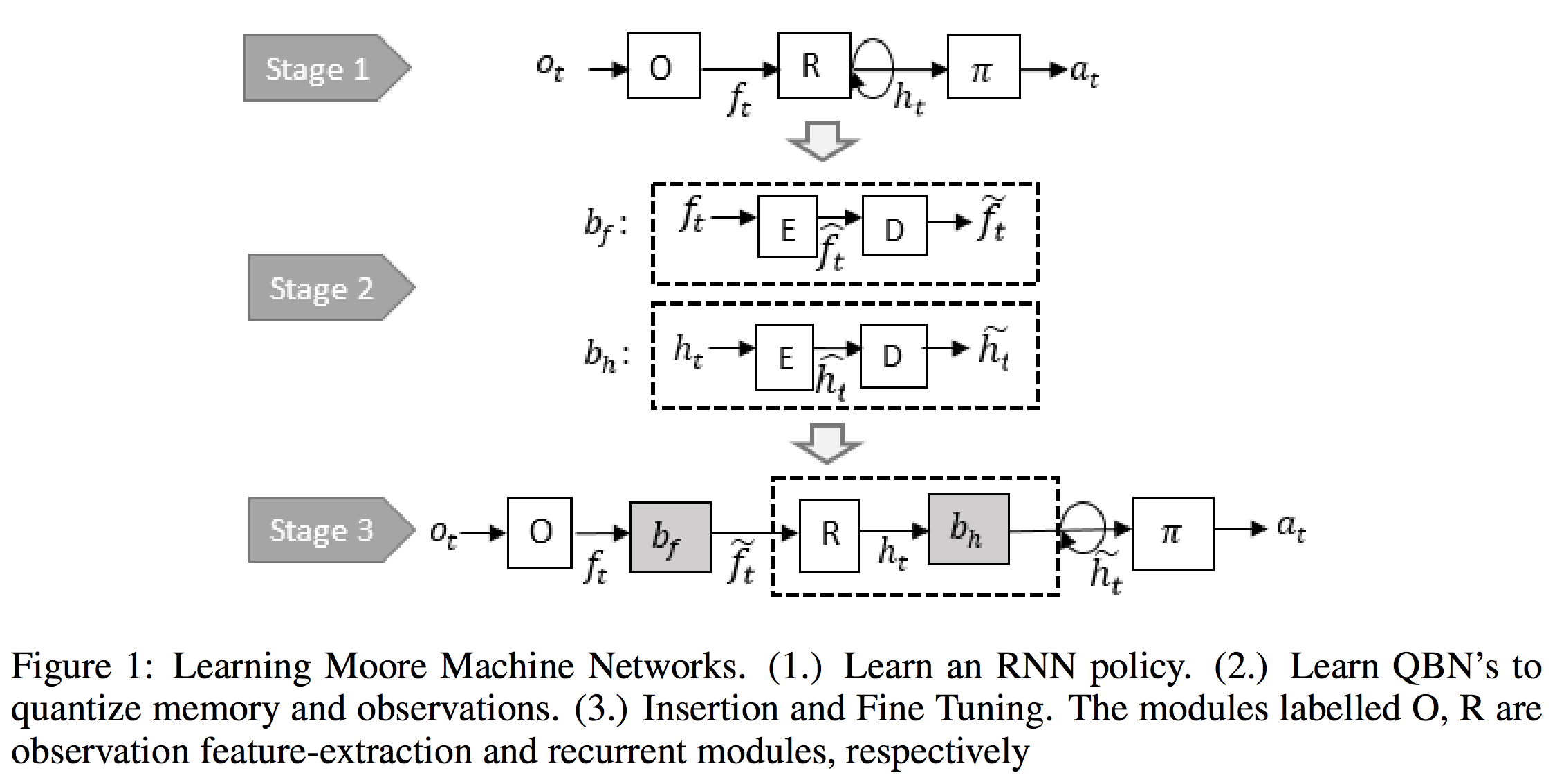
이 두 논문의 주된 동기는 RNN에서 hidden state가 매우 많기 때문에 상태의 수를 줄일 수 있다는 것입니다. DFA가 언어에 대한 RNN을 효과적으로 표현할 수 있다는 것에는 회의적이지만, Koul et al. 의 논문에서 제시한 바와 같이 훈련 중에 RNN을 학습한 다음 이를 DFA로 변환하는 아이디어를 정말 좋아합니다. Pong 게임에서는 3개의 이산 메모리 상태(discrete memory state)와 10회의 관찰이 필요합니다. 유한 상태 표현 또한 RNN 해석이 도움이 됩니다.
4. RNN is losing its luster with researchers
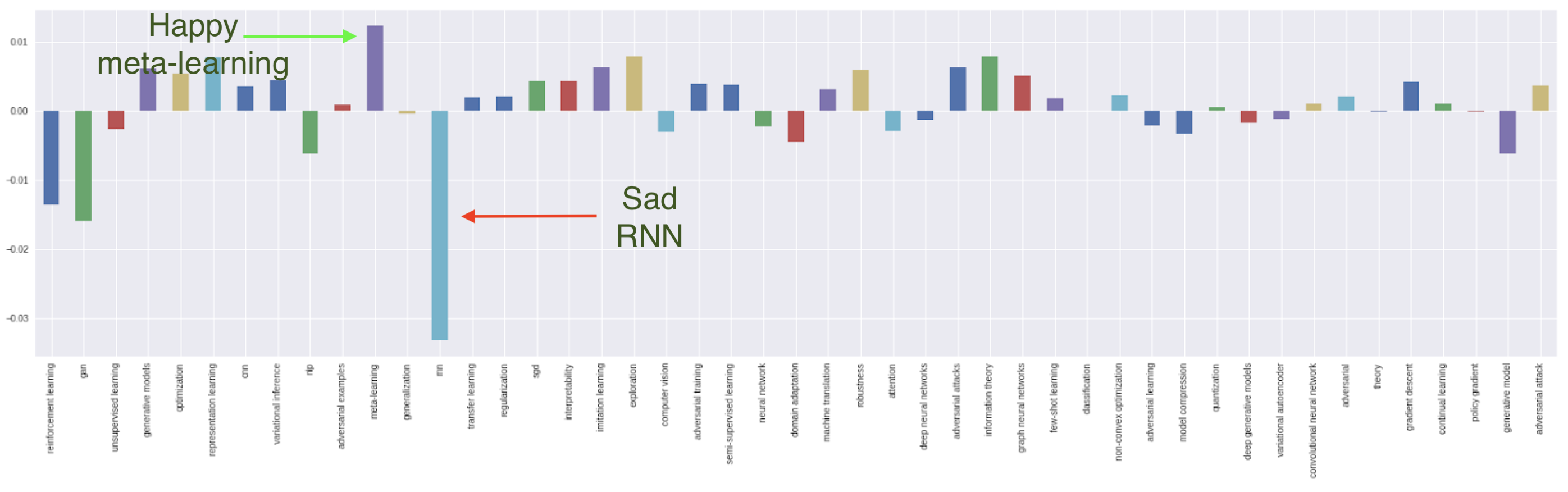
2018년과 비교하여 2019년 submissions topics의 상대적인 변화는 RNN이 가장 크게 줄었다는 점입니다.
하지만 이는 놀랄 일이 아닌게, RNN은 순차적인 데이터에 대해 직관적인 반면 대규모 처리시 컴퓨팅 파워로 고통받기 때문입니다. (병렬처리를 할 수 없고, 병렬 처리는 2012년부터 연구의 가속화를 시킨 핵심 요인이기 때문입니다.)
RNN은 CV나 RL에서는 인기가 있던 적이 없으며, NLP의 경우에는 이제 attention 기반으로 대체되었습니다.
이것은 RNN이 죽었다는 뜻일까요? 그것은 아닙니다.
올해 최고의 논문 상을 받은 두 개의 논문 중 하나는 “Ordered neurons: Integrating tree structures into Recurrent Neural Networks.” (Shen et al.) 입니다. 이 외에도 위에서 언급한 2개의 오토마타 논문까지 합해 총 9개의 논문이 올해 accepted 되었습니다. 이 중 대부분의 논문은 RNN에 대한 새로운 응용 프로그램을 만드는 대신 수학적인 부분으로 깊게 연구하였습니다.
RNN은 여전히 업계에서 살아있으며, 특히 무역 회사 등 시계열 데이터를 다루는 회사에서는 흔히 볼 수 있습니다. 하지만 이런 업계들은 보통 publish하지 않습니다.
RNN이 지금 연구원들에게는 매력적이지 않지만, 미래에는 다시 돌아올지 누가 알까요?
5. GANs are still going on strong
작년에 비해 GAN이 상대적으로 negative한 변화를 보였음에도 실제로 논문수는 약 70건에서 100건으로 증가하였습니다.
Ian Goodfellow는 GAN관련 여러 강연에 초청되었고, 많은 추종자에 의해 끊임없이 휩쓸렸습니다. 마지막 날에는 사람들이 자신의 이름을 보지 못하도록 배지를 뒤집어 놓아야했습니다.
첫 번째 포스터 세션은 전체가 GAN이었습니다.
- 새로운 GAN 아키텍처
- 기존 GAN 아키텍처 개선
- GAN 분석
- 이미지, 텍스트, 오디오 등의 GAN Application
또한 PATE-GAN, GANSynth, ProbGAN, InstaGAN, RelGAN, MisGAN, SPIGAN, LayoutGAN, KnockoffGAN 등이 있었으나, GAN literature(여기서는 GAN 명명법을 의미하는 것 같습니다.)에 대해 아는바가 없어 이를 이해할 수 없었습니다. 또한 Andrew Brock의 large scale GAN 모델을 giGANtic이라 하지 않아 매우 아쉬웠습니다. (번역을 할까말까하다가 재밌어서 그냥 가져왔습니다:-) )

GAN 포스터 세션은 커뮤니티가 얼마나 양극화되어 있는지 보여줍니다. GAN 분야가 아닌 사람들에게는 다음과 같은 말들도 들었습니다.
“GAN 같은 것들이 모두 날아갈 때까지 기다릴 수 없다.” “누군가 GAN의 A만 말해도 내 뇌는 셧다운된다.”
내(작성자)가 아는한, 그들은 그냥 질투인 것 같습니다.
6. The lack of biologically inspired deep learning
Gene sequencing과 CRISPR 아기에 관한 모든 소동을 감안할 때, ICLR에 생물학에 대한 딥러닝 논문이 더 없다는 것은 매우 놀랍습니다. 총 6개의 논문이 있습니다.
2개의 biologically-inspired architectures 논문과
- Biologically-Plausible Learning Algorithms Can Scale to Large Datasets (Xiao et al.)
- A Unified Theory of Early Visual Representations from Retina to Cortex through Anatomically Constrained Deep CNNs (Lindsey et al.) One on Learning to Design RNA (Runge et al.)
1개는 Learning to Design RNA (Runge et al.)이며,
3개의 Protein manipulation 논문이 있습니다.
- Human-level Protein Localization with Convolutional Neural Networks (Rumetshofer et al.)
- Learning Protein Structure with a Differentiable Simulator (Ingraham et al.)
- Learning protein sequence embeddings using information from structure (Bepler et al.)
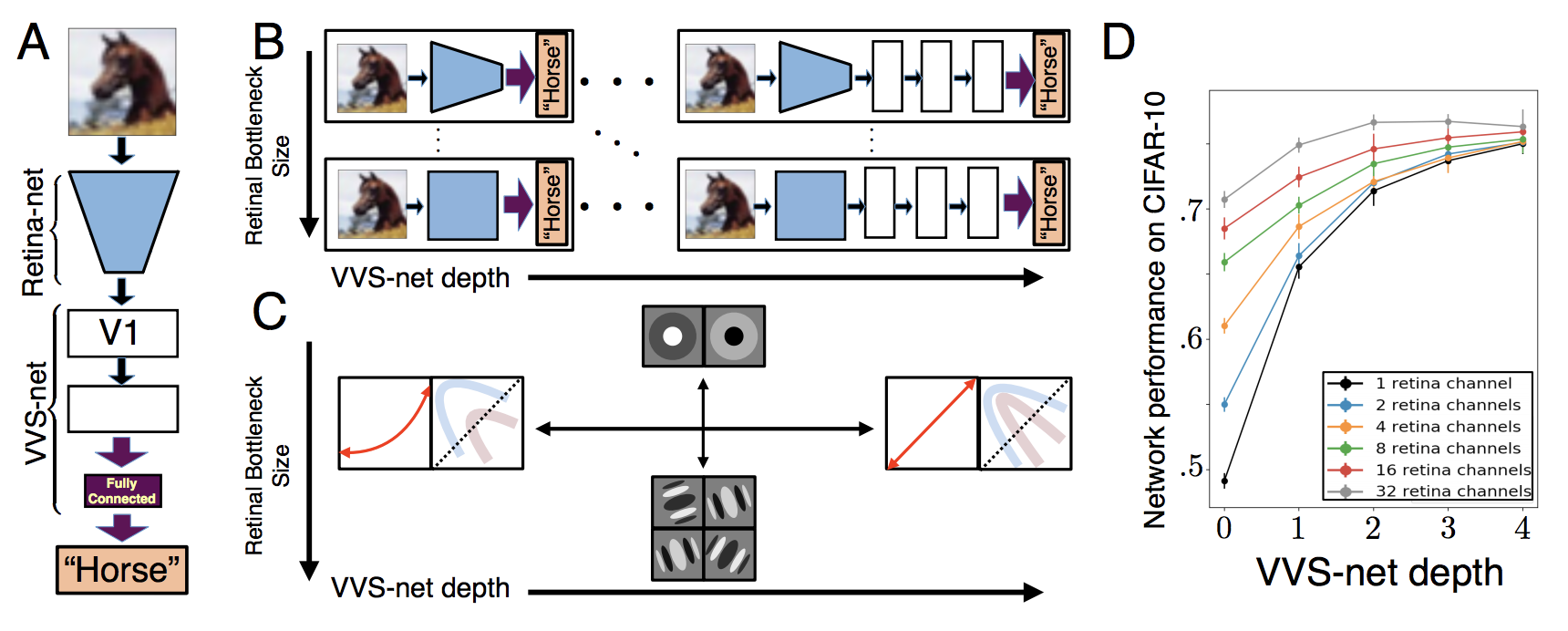
유전학에 관한 논문은 없습니다. 또한 주제에 대한 워크샵도 없었습니다. 이 사실은 슬프지만, 한편으로는 생물학자나 생물학에 관심이 많은 딥러닝 연구자에게는 큰 기회가 될 수 있다는 것을 보여줍니다.
TMI : retina 논문의 1저자인 Jack Lindsey는 스탠포드에서 학부 4학년 중인 학생입니다. 요즘 애들이란 ㄷㄷㄷ (역자의 말 : 저랑 학년이 같다는게 믿기지 않네요. 전 언제 이정도 수준까지 성장할까요.)
7. Reinforcement learning is still the most popular topic by submissions
컨퍼런스에서 발표된 내용들은 RL 커뮤니티가 model-free method에서 sample-efficient model-based and meta-learning algorithms으로 트렌드가 움직이는 것을 보여줍니다.
이는 TD3 (Fujimoto et al., 2018) and SAC (Haarnoja et al., 2018)에 의해 설정된 Mojuco 연속 제어 벤치마크가 높은 score를 얻은 것과 R2D2 (Kapturowski et al., ICLR 2019)에 의해 설정한 Atari discrete control tasks가 기여한 것으로 보입니다.
모델 기반 알고리즘은 드디어 model-free을 상대로 점근적 성능(asympototic performace)에 도달하였고, 10~100배 적은 experience를 사용하였습니다. (MB-MPO (Rothfuss et al.)).
이러한 장점으로 real-world에 적합합니다. 단일 학습된 시뮬레이터에 결함이 있을 수 있지만, 시뮬레이터의 앙상블과 같은 복잡한 다이나믹 모델을 사용하여 오류를 완화할 수 있습니다. (Rajeswaran et al.) RL을 real world 문제에 적용하는 또 다른 방법은 시뮬레이터가 임의로 복잡한 랜덤화를 지원할 수 있게 하는 것입니다. 다양한 시뮬레이션 환경에서 교육된 policy는 real world의 무작위성을 고려하여 이를 성공시킵니다. (OpenAI)
빠른 transfer learning을 수행하는 Meta-learning 알고리즘은 샘플 효율성(sample-efficiency)와 성능면에서 많이 개선되었습니다. )(ProMP (Rothfuss et al.), PEARL (Rakelly et al.)) 이러한 개선으로 다른 작업에서 배운 policy를 다시 시작할 필요가 없을 것이고, 우리는 “RL의 ImageNet화”에 더 근접하게 되었습니다.
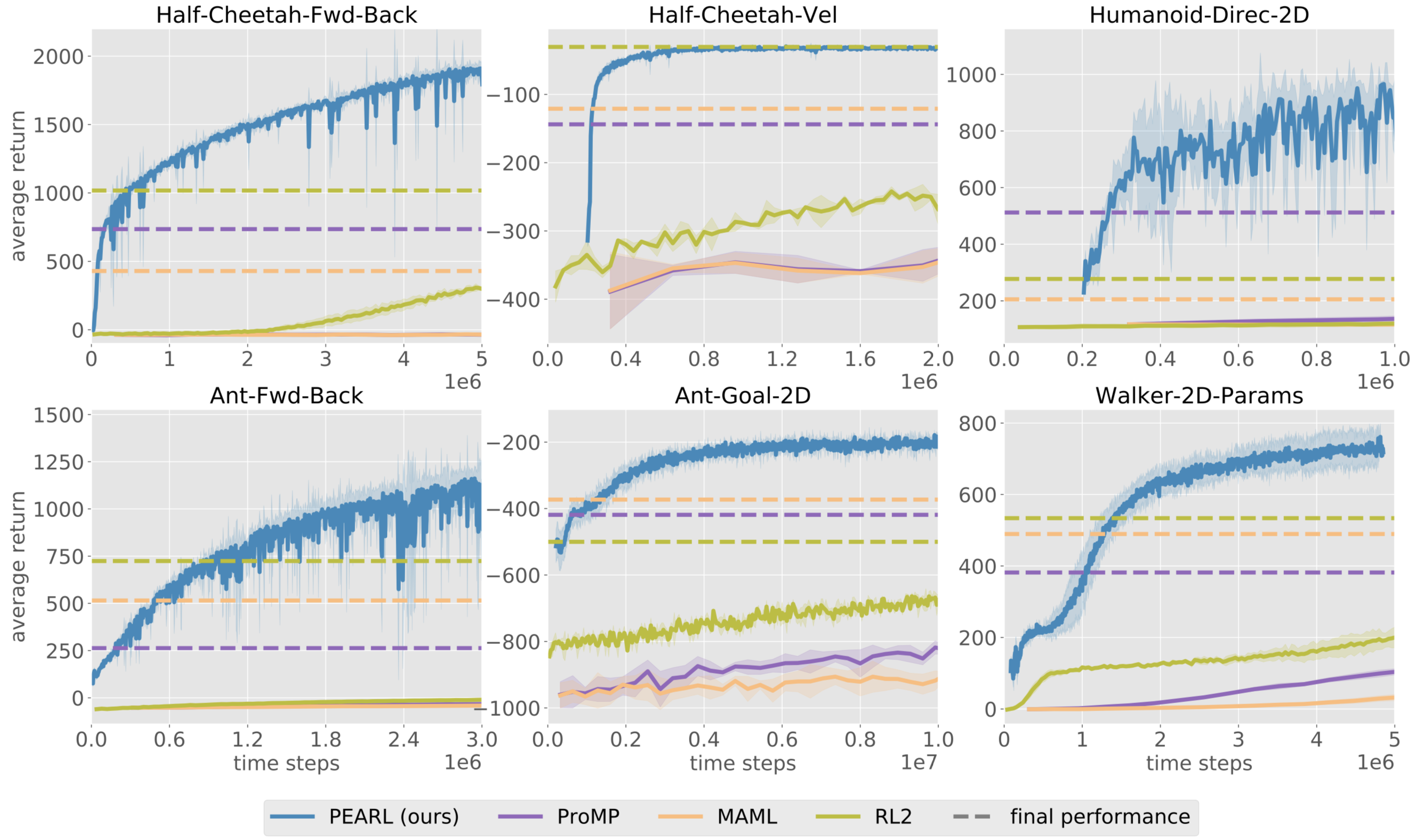
RL 워크샵과 accepted된 논문 등 전체적인 RL에서 많은 부분이 환경에 관한 일부 지식을 학습 알고리즘에 통합하는 것에 전념하였습니다. 초기에 deep RL 알고리즘의 주요 장점 중 하나는 일반성 이 었지만 새로운 알고리즘은 사전 지식을 통합하면 보다 복잡한 작업에 도움이 된다는 것을 보여줍니다. 예시로 Transporter Network (Jakab et al.)에서 에이전트는 사전 지식을 사용하여 보다 유익한 구조 탐색(informative structural exploration)을 수행합니다.
요약하면, 지난 5년간 RL 커뮤니티는 model-free 설정에서 RL 문제를 해결하기 위해 다양한 효율적 도구를 개발했습니다. 이제는 RL을 real world에 적용하기 위해 효율이 높고, 전달 가능한 알고리즘을 찾아야 할 때입니다.
TMI : Sergey Levine은 올해 ICLR에서 가장 많은 논문을 accepted 받은 사람으로 선정되었고, 총 15개의 논문을 accepted 받았습니다.
8. Most accepted papers will be quickly forgotten
올해 잘 알려진 연구원분에게 올해 논문에 대해 의견을 물었더니 이런 답을 받았습니다.
이 중 대다수는 컨퍼런스가 끝나자마자 대부분은 잊혀질 것입니다.
머신러닝만큼 빨리 움직이는 분야에서 state-of-the-art 결과들은 몇주일만에 깨집니다. 며칠이 아니더라도 accepted된 대부분의 논문들은 이미 발표된 시점보다 더 발전하고 있다는 점은 놀라울 일이 아닙니다.
예시로 Borealis AI, ICLR2018, “seven out of eight defense papers were broken before the ICLR conference even started.”
컨퍼런스에서 자주 들었던 의견 중 하나는 acceptance/rejection의 무작위성입니다. 언급하지는 않겠지만 일부 가장 많이 언급되고 인용되는 논문들은 기존에 제출하고자 했던 컨퍼런스에서 reject되었습니다.
현장에서 연구하는 사람 중 하나로 가끔 실존적 위기를 마주합니다. 내가 가지고 있는 아이디어가 무엇이든, 다른 누군가가 이미 더 잘하고 더 빨리하고 있는 것처럼 보입니다. 누구에게도 필요가 없는 논문을 publish하는 것의 요지는 무엇일까요? 누군가 도와주세요!!
Conclusion
확실히 다루고 싶은 트렌드 중에서는 다음과 같은 내용들이 있었습니다.
- optimizations and regularizations : Adam과 SGD는 여전히 논쟁중입니다. 많은 새로운 테크닉이 제안되었고, 꽤 흥미로운 내용이 많습니다. 최근에는 모든 lab에서 자체적인 옵티마이저를 개발하고 있는 것 같습니다. 우리 팀도 조만간 출시할 새로운 옵티마이저를 개발하고 있습니다.
- evaluation metrics : 생성 모델이 점점 대중화되면서 생성 된 결과를 평가할 수 있는 기준이 필요합니다. open-domain dialogues and GAN-generated images와 같이 생성된 구조화 데이터에 대한 metric은 매우 의심스럽고, 여전히 미지의 영역입니다.
게시물이 길어지고 있고, 저도(작성자) 다시 일하러 가야합니다. 더 많은 내용은 David Abel이 출판한 detailed notes (55 pages)을 참고하면 됩니다. ICLR2019에서 어떤 것이 핫했는지는 보충 통계 자료에서 찾을 수 있었습니다.
컨퍼런스에서 얻은 가장 좋은 것은 아이디어 뿐만 아니라 동기부여 입니다. 내 나이의 연구자들이 멋진 일을 하는 것과 아름다운 연구를 보여 동기부여를 얻을 수 있었습니다. 논문과 친구를 위해 일주일 시간을 잡는 것도 좋았습니다. 10점 만점에 10점입니다. 추천합니다.
역자의 말 : 읽으면서 마치 ICLR에 있는 기분을 느꼈습니다. 이 글을 읽는 것만으로도 동기부여가 되는 글이네요.
Leave a Comment