머신러닝 모델과 해석을 분리하면(= 모델 독립적 해석 방법, model-agnostic interpretation methods) 몇 가지 장점이 있습니다. (Ribeiro, Singh, and Guestrin 20161).
모델 별 해석 방법보다 유연하다는 것입니다. 머신러닝 개발자는 모델에 구애받지 않고, 원하는 모델에 따라 해석을 진행할 수 있습니다. 모델 해석에 있어 그래픽 또는 UI 등에 있어 모델과는 모두 독립적입니다. 일반적으로 하나가 아닌 다수의 모델을 사용하여 문제를 해결하고, 후에 해석에 따른 모델 비교에 있어 모델 독립적이므로 모든 모델에 같은 방법을 적용하여 쉽게 비교할 수 있습니다.
모델 독립적 해석 방법의 대안책으로는 해석 가능한 모델(Interpretable Model)을 사용하면 되는데, 이 방법은 종종 예측 성능이 떨어지고 한 가지 모델로 제한된다는 단점이 있습니다. 다른 방법으로는 모델 별 해석 방법(model-specific interpretation method)을 사용하는 것인데, 이것 또한 하나의 모델 유형에 한정되며 다른 모델로 전환이 어렵다는 것입니다. (역자의 말 : 해석 가능한 모델과 모델별 해석에 대한 구분은 모르겠습니다.)
모델에 구애받지 않는 설명 시스템의 바람직한 방향은 다음과 같습니다. (Ribeiro, Singh, and Guestrin 2016):
-
모델 유연성(Model flexibility): 해석 방법은 딥러닝, 랜덤 포레스트 등의 모델에 구애받지 않아야 합니다.
-
해석 유연성(Explanation flexibility): 특정 형태로 설명이 한정되어서는 안됩니다. 경우에 따라 선형 수식, 피처 중요도(feature importance)에 따른 그래픽(차트) 등이 유용할 수 있습니다.
-
표현 유연성(Representation flexibility): 설명 시스템은 feature에 따라 모델을 설명할 수 있어야 합니다. 예를 들어 word embedding을 사용하는 text classification은 특정 word의 존재를 설명에 사용하는 것이 좋습니다.
The Bigger Ficture
Let us take a high level look at model-agnostic interpretability. We capture the world by collecting data, and abstract it further by learning to predict the data (for the task) with a machine learning model. Interpretability is just another layer on top that helps humans understand.
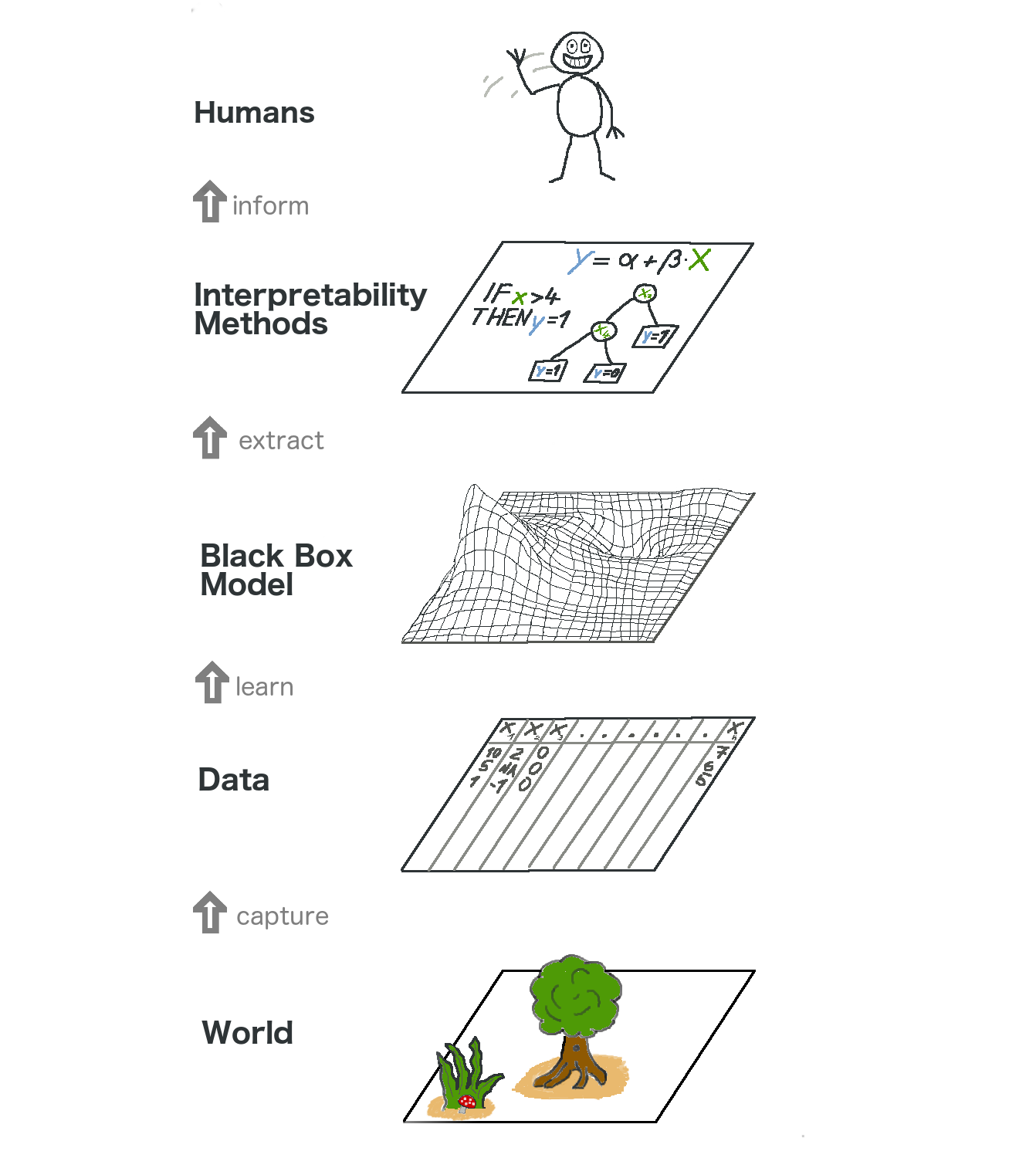
The lowest layer is the World. This could literally be nature itself, like the biology of the human body and how it reacts to medication, but also more abstract things like the real estate market. The World layer contains everything that can be observed and is of interest. Ultimately, we want to learn something about the World and interact with it.
The second layer is the Data layer. We have to digitize the World in order to make it processable for computers and also to store information. The Data layer contains anything from images, texts, tabular data and so on.
By fitting machine learning models based on the Data layer, we get the Black Box Model layer. Machine learning algorithms learn with data from the real world to make predictions or find structures.
Above the Black Box Model layer is the Interpretability Methods layer, which helps us deal with the opacity of machine learning models. What were the most important features for a particular diagnosis? Why was a financial transaction classified as fraud?
The last layer is occupied by a Human. Look! This one waves to you because you are reading this book and helping to provide better explanations for black box models! Humans are ultimately the consumers of the explanations.
This multi-layered abstraction also helps to understand the differences in approaches between statisticians and machine learning practitioners. Statisticians deal with the Data layer, such as planning clinical trials or designing surveys. They skip the Black Box Model layer and go right to the Interpretability Methods layer. Machine learning specialists also deal with the Data layer, such as collecting labeled samples of skin cancer images or crawling Wikipedia. Then they train a black box machine learning model. The Interpretability Methods layer is skipped and humans directly deal with the black box model predictions. It’s great that interpretable machine learning fuses the work of statisticians and machine learning specialists.
Of course this graphic does not capture everything: Data could come from simulations. Black box models also output predictions that might not even reach humans, but only supply other machines, and so on. But overall it is a useful abstraction to understand how interpretability becomes this new layer on top of machine learning models.
-
Ribeiro, Marco Tulio, Sameer Singh, and Carlos Guestrin. “Model-agnostic interpretability of machine learning.” ICML Workshop on Human Interpretability in Machine Learning. (2016). ↩