K E R A S … T a s t y …
본 문서는 [케라스 창시자에게 배우는 딥러닝] 책을 기반으로 하고 있으며, subinium(본인)이 정리하고 추가한 내용입니다. 생략된 부분과 추가된 부분이 있으니 추가/수정하면 좋을 것 같은 부분은 댓글로 이야기해주시면 감사하겠습니다.
본 장은 케라스에 대한 소개와 케라스로 할 수 있는 예시를 진행합니다.
3.1 신경망의 구조
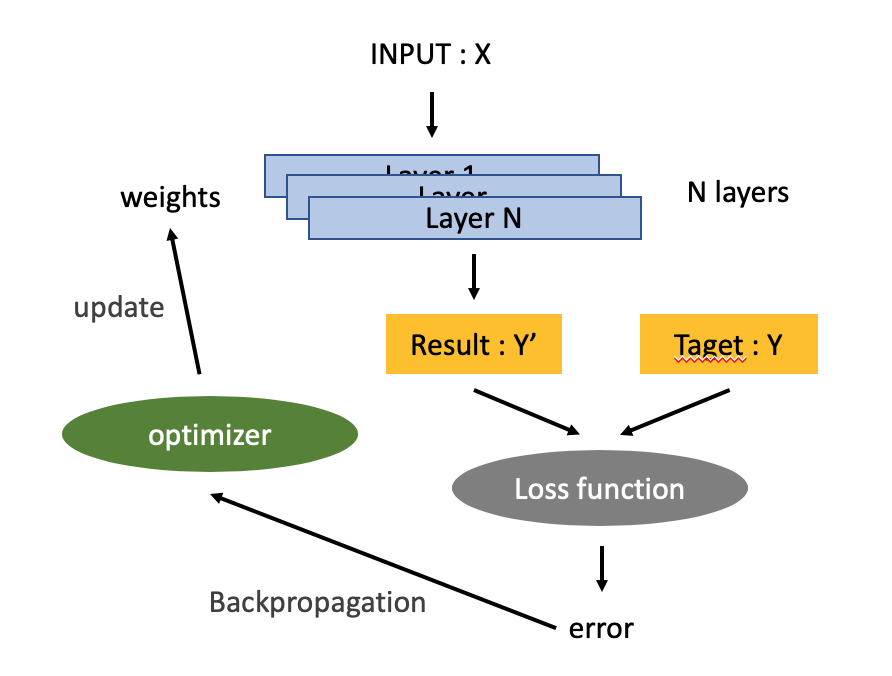
신경망 훈련에는 다음 요소들이 관련되어 있습니다.
- 네트워크를 구성하는 층
- 입력 데이터와 그에 상응하는 타깃
- 학습에 사용할 피드백 신호를 정의하는 손실 함수
- 학습 진행 방식을 결정하는 옵티마이저
이들의 상호학습은 이전에도 나타냈지만, 다음 그림으로 표현할 수 있습니다.
3.1.1 층: 딥러닝의 구성 단위
층 이란 하나 이상의 텐서를 입력으로 받아 하나 이상의 텐서를 출력하는 데이터 처리 모듈입니다. 대부분의 층은 가중치 라는 층의 상태를 가지게 됩니다. 여기서 가중치는 확률적 경사 하강법에 의해 학습되는 하나 이상의 텐서이며 여기에 네트워크가 학습한 지식이 포함되어 있습니다.
층마다 적절한 텐서 포맷과 데이터 처리 방식이 다릅니다.
- 2D : 완전 연결 층이나 밀집 층이라 불리는 밀집 연결 층
- 3D : 순환 층
- 4D : 2D 합성곱 층
이런 다양한 층을 구성하여 네트워크를 만드는데, 케라스에서는 이를 레고 블럭과 같이 생각할 수 있습니다. 그 이유는 층 호환성(layer compatibility) 에 따라서 호환 가능한 층 등을 엮어 데이터 변환 파이프라인(pipeline)을 구성하여 모델을 만들기 때문입니다. 특정 크기의 입력을 받고, 특정 크기의 출력 텐서를 반환하는 것 입니다. 케라스에서는 그렇기에 다음과 같은 코드가 가능합니다.
from keras import models
from keras import layers
model = models.Sequential()
model.add(layers.Dense(32. input_shape=(784,)))
model.add(layer.Dense(10))
위에서 모델에 2 종류의 층을 만듭니다. 처음에는 784차원인 2D 텐서를 입력으로 받습니다. 그 후에는 input에 대한 제한 없이 층을 만듭니다. 케라스에서는 모델에 추가된 층을 자동으로 상위 층의 크기에 맞추어주기 때문에 다음과 같이 작성하면 두 번째 층은 첫 번째 층의 출력 크기를 입력 크기로 자동 채택합니다.
3.1.2 모델: 층의 네트워크
딥러닝 모델은 층으로 만든 비순환 유향 그래프(DAG)입니다. 가장 일반적인 예시는 하나의 입력을 하나의 출력으로 매핑하는 층을 순서대로 쌓는 것입니다. 하지만 네트워크는 다양한 구조를 지닙니다.
- 가지(branch)가 2개인 네트워크
- 출력이 여러 개인 네트워크
- 인셉션(Inception) 블록
네트워크는 가설 공간(hypothesis space) 을 정의합니다. 네트워크 구조를 선택함으로싸 가설 공간을 입력 데이터에서 출력 데이터로 매칭하는 일련의 특정 텐서 연산으로 제한하게 됩니다. 딥러닝에서는 텐서 연산에 사용되는 가중치의 최적 값을 찾는 것을 목표로 합니다.
3.1.3 손실 함수와 옵티마이저: 학습 과정을 조절하는 열쇠
네트워크 구조를 정의하고 나면 두 가지를 더 선택합니다.
- 손실함수 또는 목적함수 : 훈련하는 동안 최소화될 값, 성공 지표
- 옵티마이저 : 손실 함수를 기반으로 네트워크 업데이트를 결정, 특정 종류의 SGD(확률적 경사 하강법)을 구현
여러 개의 출력을 내는 신경망은 여러 개의 손실 함수를 가질 수 있습니다. (출력당 하나씩) 그러나 경사 하강법 과정은 하나의 손실 value를 필요로 하므로, 손실 함수가 여러개인 케이스는 스칼라의 합과 평균으로 계산합니다.
목적 함수는 매우 중요한데, 다음과 같은 링크에 예시들을 보면 좋을 것 같습니다.
위의 링크와 같이 딥러닝은 결과값의 최적화만을 목표로 하므로, 문제에 대한 설정, 제한을 정의하는 목적함수가 중요합니다.
일반적인 문제에서는 다음과 같은 간단한 지침이 있다고 합니다.
- 2개의 클래스 분류 문제 : 이진 크로스엔트로피
- 여러 클래스 분류 문제 : 범주형 크로스엔트로피
- 회귀 문제 : 평균 제곱 오차
- 시퀀스 학습 문제 : CTC
3.2 케라스 소개
지금까지 케라스 소개한 줄 알았는데 책에서 또 소개한다고 합니다. (알쓸신잡 : keras는 그리스어로 뿔을 의미합니다.)
케라스는 다음과 같은 특징을 지니고 있습니다.
- 동일한 코드로 CPU와 GPU에서 실행할 수 있습니다.
- 사용하기 쉬운 API를 가지고 있어 딥러닝 모델의 프로토타입을 빠르게 만들 수 있습니다.
- 합성곱 신경망, 순환 신경망을 지원하며 이 둘을 자유롭게 조합하여 사용할 수 있습니다.
- 어떤 네트워크 구조도 만들 수 있습니다.
- MIT 라이선스를 따르므로 상업적인 프로젝트에도 자유롭게 사용할 수 있습니다.
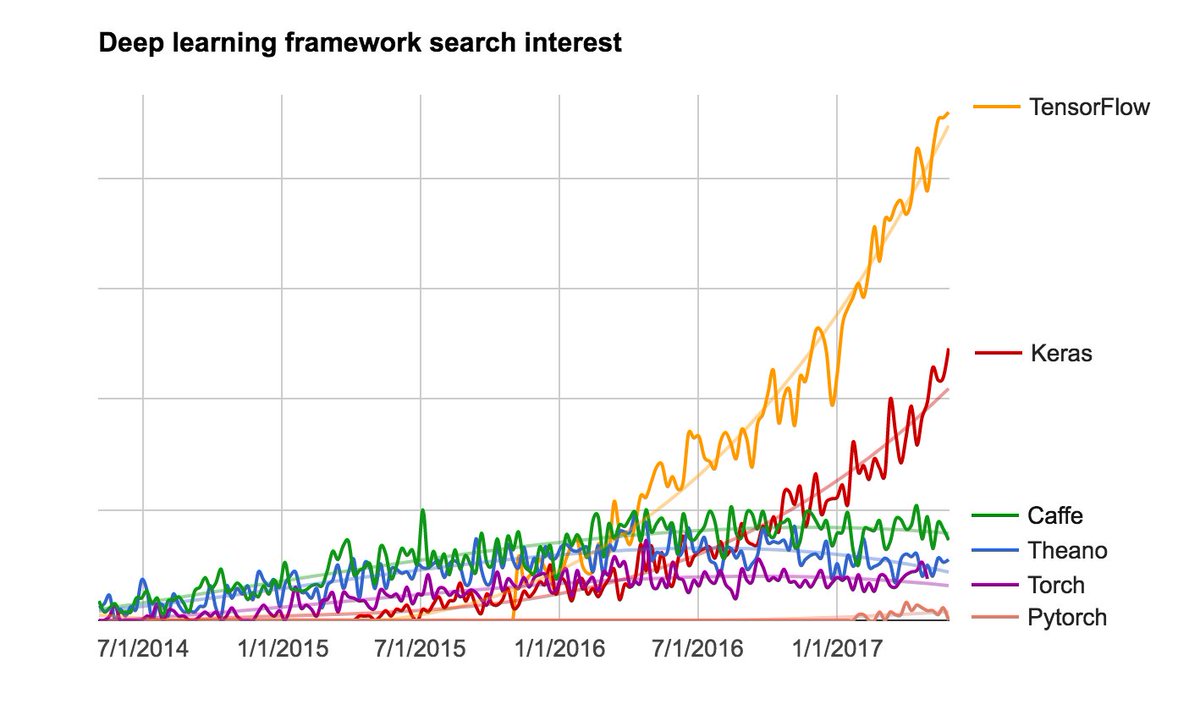
3.2.1 케라스, 텐서플로, 씨아노, CNTK
케라스는 딥러닝 모델을 만들기 위한 고수준의 궝 요소를 제공하는 모델 수준의 라이브러리입니다. 텐서 조작이나 미분 같은 저수준의 연산을 다루지 않습니다. 대신 케라스의 백엔드 엔진에서 제공하는 최적화되고 특화된 텐서 라이브러리를 사용합니다. 즉 여러 딥러닝용 라이브러리를 조합하여 사용하는 것입니다.
현재는 3개의 백엔드 엔진을 사용하고 있습니다. 공식페이지 참조
- 텐서플로(tensorflow)
- CNTK
- 씨아노(theano)
케라스에는 다음 백엔드 엔진을 필요에 따라서 선택하여 사용할 수 있습니다. 다음 벡엔드를 사용하기에 CPU와 GPU에서 모두 사용할 수 있습니다. CPU에서는 저수준 텐서 연산 라이브러리인 Eigen을, GPU에서는 NVIDIA CUDA 심층 신경망 라이브러리를 사용하여 최적화된 딥러닝 연산 라이브러리를 이용합니다.
3.2.2 케라스를 사용한 개발: 빠르게 둘러보기
전형적인 케라스 작업 흐름은 다음과 같은 흐름을 지닙니다.
- 입력 텐서와 타깃 텐서로 이루어진 훈련 데이터를 정의합니다.
- 입력과 타깃을 매핑하는 층으로 이루어진 네트워크를 정의합니다.
- 손실함수, 옵티마이저, 모니터링하기 위한 측정 지표를 선택하여 학습 과정을 설정합니다.
- 훈련 데이터에 대해 모델의 fit() 메서드를 반복적으로 호출합니다.
모델은 두가지 방법으로 정의합니다.
- Sequential 클래스 : 순서대로 층을 쌓아올리는 경우
- 함수형 API : 임의의 구조를 만들 수 있는 비순환 유향 그래프
같은 모델을 작성하였을때, 다음과 같은 차이가 있습니다.
# Sequential 사용
from keras import models
from keras import layers
model = models.Sequential()
model.add(layers.Dense(32,activation='relu'. input_shape=(784,)))
model.add(layers.Dense(10, activation='softmax'))
# 함수형 API
input_tensor = layers.Input(shape=(784,))
x = layers.Dense(32, activation='relu')(input_tensor)
output_tensor = layers.Dense(10,activation='softmax')(x)
model = models.Model(input=input_tensor, output=output_tensor)
모델이 정의된 후에는 동일한 단계를 거치게 됩니다. 컴파일 단계에서는 학습 과정이 설정됩니다. 여기서는 옵티마이저, 손실함수, 모니터링에 필요한 측정 지쵸를 지정합니다. 그리고 마지막에 fit() 메서드에 전달함으로 학습 과정이 이루어집니다.
# 학습과 fit()
from keras import optimizers
model.compile(optimizer=optimizers.RMSprop(lr=0.001), loss='mse',metrics=[accuracy])
model.fit(input_tensor, target_tensor, batch_size=128, epochs=10)
3.3 딥러닝 컴퓨터 셋팅
저번에 케라스 예시를 진행하며 느낀점은 머신 러닝은 ‘CPU로 돌리면 안된다’ 였습니다. 문제점은 다음과 같습니다.
- 너무 느리다. 검색 결과 GPU와 비교하였을 때, 최소 5~10배 이상 차이..
- CPU가 무리하는 게 느껴집니다. 2016년 초부터 MacBook Pro(Retina, 15-inch, Mid 2014)를 사용하고 있습니다. 현재 상태가 간당간당하기에 케라스 MNIST 예제 돌리는 것도 팬 소리가 에어컨 소리정도 납니다.
그렇기에 GPU를 사용하거나 Cloud를 통해 돌려야함을 느끼고 있습니다. 일단 내용을 정리하며 어떻게 할지 결정해야겠습니다.
3.3.1 주피터 노트북: 딥러닝 실험을 위한 최적의 방법
주피터 노트북(Jupyter Notebook)은 딥러닝 실험, 예제 코드를 위한 최적의 방법이라고 합니다. 이 방법은 다음과 같은 특징을 지니고 있습니다.
- 노트북 은 주피터 노트북 어플리케이션으로 만든 파일이며 웹 브라우저에서 작성 가능
- 작업 내용을 기술하기 위해 서식 있는 텍스트 포맷을 지원하며 파이썬 코드 실행 가능
- 긴 코드를 작게 쪼개 독립적 실행 가능, 대화식 개발 가능
- 작업 중 잘못되었을 때 이전 코드를 모두 재실행할 필요 없음
3.3.2 케라스 시작하기: 두 가지 방법
위에서 말했듯 본격적인 시작은 두 가지 방법으로 나눌 수 있습니다.
- 공식 EC2 딥러닝 AMI을 사용하여 EC2에서 주피터 노트북으로 케라스 예제를 실행
- GPU가 있을 경우, 로컬 컴퓨터에서 실행
각각의 장단점은 다음과 같습니다.
3.3.3 클라우드에서 딥러닝 작업을 수행했을 때 장단점
클라우드에서 실행하면 GPU를 사지않고 간단하고 저렴하게 사용할 수 있습니다. 하지만 장기적으로 한다면 적합하지 않습니다. AWS EC2 인스턴스는 비쌉니다.
다음은 딥러닝을 위하여 AWS EC2를 설정하는 방법에 대한 링크입니다.
3.3.4 어떤 GPU 카드가 딥러닝에 최적일까?
책에서는 NVIDIA GPU를 권장한다. GPU의 경우 다음과 같은 글을 참고하면 좋을 것 같습니다.
링크를 들어가면 딥러닝 공부 유형에 따라 GPU 추천해주고 있다. 작년까지만 해도 모두 GTX 1060을 가장 많이 추천해주었는데, 가격대가 안정되고 시간이 지남에 따라 선택할 수 있는 범위가 넓어진 것 같습니다.
- Best GPU overall: RTX 2070
- GPUs to avoid: Any Tesla card; any Quadro card; any Founders Edition card; Titan V, Titan XP
- Cost-efficient but expensive: RTX 2070
- Cost-efficient and cheap: GTX Titan (Pascal) from eBay, GTX 1060 (6GB), GTX 1050 Ti (4GB)
- I have little money: GTX Titan (Pascal) from eBay, or GTX 1060 (6GB), or GTX 1050 Ti (4GB)
- I have almost no money: GTX 1050 Ti (4GB); CPU (prototyping) + AWS/TPU (training); or Colab.
- I do Kaggle: RTX 2070. If you do not have enough money go for a GTX 1060 (6GB) or GTX Titan (Pascal) from eBay for prototyping and AWS for final training. Use fastai library
- I am a competitive computer vision or machine translation researcher: GTX 2080 Ti with the blower fan design; upgrade to RTX Titan in 2019
- I am an NLP researcher: RTX 2070 use 16-bit.
- I want to build a GPU cluster: This is really complicated, you can get some ideas here
- I started deep learning and I am serious about it: Start with an RTX 2070. Buy more RTX 2070 after 6-9 months and you still want to invest more time into deep learning. Depending on what area you choose next (startup, Kaggle, research, applied deep learning) sell your GPU and buy something more appropriate after about two years.
- I want to try deep learning, but I am not serious about it: GTX 1050 Ti (4 or 2GB). This often fits into your standard desktop. If it does, do not buy a new computer!
RTX 2070은 가격대를 보니 60만원 내외인 것 같습니다. 쉽게 사기는 어려운 가격이나 고려는 해봐야겠습니다.
3장을 2개로 나누는 이유
왜냐하면 이런 상황에 처했기 때문입니다. 일단 GPU를 바로 사는 것은 무리다는 판단하에 EC2를 연결할라 하였으나…

예전에 subinium.io 블로그를 만들때, 카드를 변경하며 서버 비용을 지출하지 않았던 것입니다. 계정이 막혀버리는 일이 발생했습다!!! 계정을 버릴까 생각했지만, 어짜피 조만간 사이트를 하나 만들 생각이어서 지불할 생각입니다.
기업이나 연구실에 들어가 필요한 기구를 막 사고 싶네요. 공부 스폰서가 있으면 좋겠다는 생각을 합니다! 슬슬 공부를 위해서라도 돈을 벌어야하는데, 아직은 제가 어떤 것으로 돈을 벌 수 있을지 모르겠네요.
Leave a Comment